Azure AI Studio: How to evaluate and upgrade your models, using the Prompt Flow SDK

Let's face it: keeping up with AI model updates can feel like chasing a hyperactive squirrel. Just when you've gotten comfortable with one version, another pops up, promising to be faster, safer, and maybe even make you coffee in the morning.
But here's the thing – those shiny new models aren't just for show. They can seriously improve your AI application, potentially saving you time, money, and headaches. The flip side? Your trusty old models will eventually be put out to pasture.
This blog post will guide you through the process of evaluating new model versions and upgrading your deployments in the Azure OpenAI Service. We'll explore how to use Azure AI Studio Evaluations to compare different model versions, assess their performance, and make informed decisions about which version best suits your needs. And most importantly - find out whether a new model will really increase our applications performance or whether it will even introduce regressions.
More specifically, we'll cover:
- Using Azure AI Studio Evaluations to assess new model versions
- Comparing different models using both code-based and UI-friendly methods
- Best practices for upgrading your deployments
What is the Azure AI Studio?
Azure AI Studio is a platform within Microsoft Azure designed to help developers create and deploy AI-powered applications. It offers a range of tools for building generative AI models, suitable for developers with varying levels of experience. The platform allows users to work with existing AI models or develop custom ones using their own data.
One of Azure AI Studio's main features is its adaptability. Users can choose between pre-built AI models or customize them with proprietary data, allowing organizations to tailor solutions to their specific needs. The platform also supports team collaboration, integrating with common development tools like GitHub and Visual Studio.
The major selling point at the moment is the integration of OpenAI's models. Most of the OpenAI models can be managed and provisioned through the Azure AI Studio. You can add content filters, deploy models, log metrics, and - as we are about to see - evaluate and upgrade models, by perfectly integrating with the Prompt Flow SDK.
What is the Microsoft Prompt Flow SDK?
The Microsoft Prompt Flow SDK is a toolkit designed to assist with the development of applications based on large language models (LLMs). It provides a robust framework for developers to streamline the entire lifecycle of LLM app development, from initial prototyping to production deployment and ongoing monitoring.
Key Features and Capabilities
Prototyping and Experimentation:
- Prompt Engineering: The SDK supports advanced prompt engineering, enabling developers to experiment with different prompt configurations to optimize model outputs.
- Python Integration: Developers can integrate Python code directly into their workflows, allowing for complex logic and data manipulation alongside prompt engineering.
Testing and Evaluation:
- Unit Testing: Prompt Flow provides tools to write unit tests for LLM prompts, ensuring that changes to prompts or underlying models do not introduce regressions.
- Performance Metrics: The SDK includes performance evaluation features, allowing developers to measure the effectiveness of different prompts and configurations.
Deployment and Monitoring:
- CI/CD Integration: The SDK integrates with Continuous Integration and Continuous Deployment (CI/CD) pipelines, enabling seamless deployment of LLM applications.
- Monitoring and Logging: It provides robust monitoring tools to track the performance of deployed applications, capturing key metrics and logs for ongoing optimization.
Collaboration and Versioning:
- Version Control: Prompt Flow SDK supports version control, making it easy to track changes and collaborate on LLM projects across teams.
- Collaboration Tools: Developers can work together in a shared environment, making the development process more efficient and ensuring consistency across different versions of an application.
Extensibility:
- Custom Plugins: The SDK allows developers to create custom plugins, extending its functionality to suit specific project needs.
- Third-Party Integrations: It supports integrations with various third-party tools and platforms
Benefits of Using Prompt Flow SDK
- Efficiency: By offering a unified platform for all stages of LLM app development, the Prompt Flow SDK reduces the time and effort required to move from prototype to production.
- Quality Assurance: The built-in testing and evaluation tools help maintain high standards for LLM applications, ensuring reliable and consistent performance.
- Scalability: The SDK is designed to handle projects of any size, from small prototypes to large-scale, production-grade applications.
Why upgrade your models?
Now that we know the tools we're gonna use in this tutorial, let's take a step back and ask the question, why are we doing this? Why should we upgrade our models? Why do we even need an automated process for validating model upgrades?
The answer is two-fold:
First, the obvious one: Models tend to get better, very quickly. Looking just at the OpenAI model changelog, we see the rate of change of models:
- GPT-3.5 was released in March 2022
- GPT-3.5-turbo was released in November 2022
- GPT-4 was released in March 2023
- GPT-4-turbo was released in November 2023
- GPT-4o was released in May 2024
As we can see, a new model drops off approximately every 6 months. However, this list does not include all the minor model versions like GPT-4o-mini, GPT-3.5-turbo-16k or eg. GPT-3.5-turbo-0125. Each of these newer models offered way better performance or 10x less costs and latency, compared to the previous one - meaning, not upgrading was almost negligent.
The second reason for the need to upgrade: Microsoft and other model providers are aggressively retiring older models as new ones arrive. Microsoft Microsoft has quite transparent model deprecation policies, with one of the main statements being: models can be retired 1 year after their initial release. So, no matter how you feel towards upgrading, a year after a models release, you have to.
What to evaluate when upgrading your models?
What metrics should you consider when evaluating new model versions? The authors of the Prompt Flow SDK suggest the following evaluation criteria:
- Performance and Quality: Metrics such as groundedness, relevance, coherence, fluency, similarity, and F1 score.
- Risk and Safety: Metrics assessing violence, sexual content, self-harm, and hate/unfairness.
- Composite Metrics: Combined evaluations for question-answer pairs or chat messages, and content safety.
To give more context, these metrics are:
-
Groundedness: Measures how well the model's output aligns with factual information.
-
Relevance: Assesses how relevant the response is to the input prompt.
-
Coherence: Evaluates the logical flow of the response ('does the output make sense?').
-
Fluency: Measures the linguistic quality and naturalness of the response.
-
Similarity: Checks the similarity between model output and reference text.
-
F1 Score: Used for precision (the accuracy of the positive predictions) and recall (the ability to find all positive instances)-based evaluations.
-
Violence: Detects content that contains violent or aggressive language.
-
Sexual Content: Identifies content with sexual references or inappropriate language.
-
Self-Harm: Evaluates whether the content encourages or discusses self-harm.
-
Hate/Unfairness: Measures the presence of hateful, biased, or discriminatory language.
-
Question-Answer Pairs: Evaluates the model's responses for accuracy and completeness in a Q&A context.
-
Content Safety: Combines different risk and safety metrics to evaluate overall content safety.
As you can see, quite a lot to validate. Keep in mind that not all of these metrics are always relevant for your use case.
In the next section we finally get to the hands-on part of this tutorial, where we will evaluate a new model version using Azure AI Studio and the Prompt Flow SDK.
Hands on: Evaluating your models using Azure AI Studio and Prompt Flow
Prerequisites
Please prepare the following prerequisites before proceeding with the tutorial:
-
Sign up for Microsoft Azure AI Studio and create a project, as outlined here.
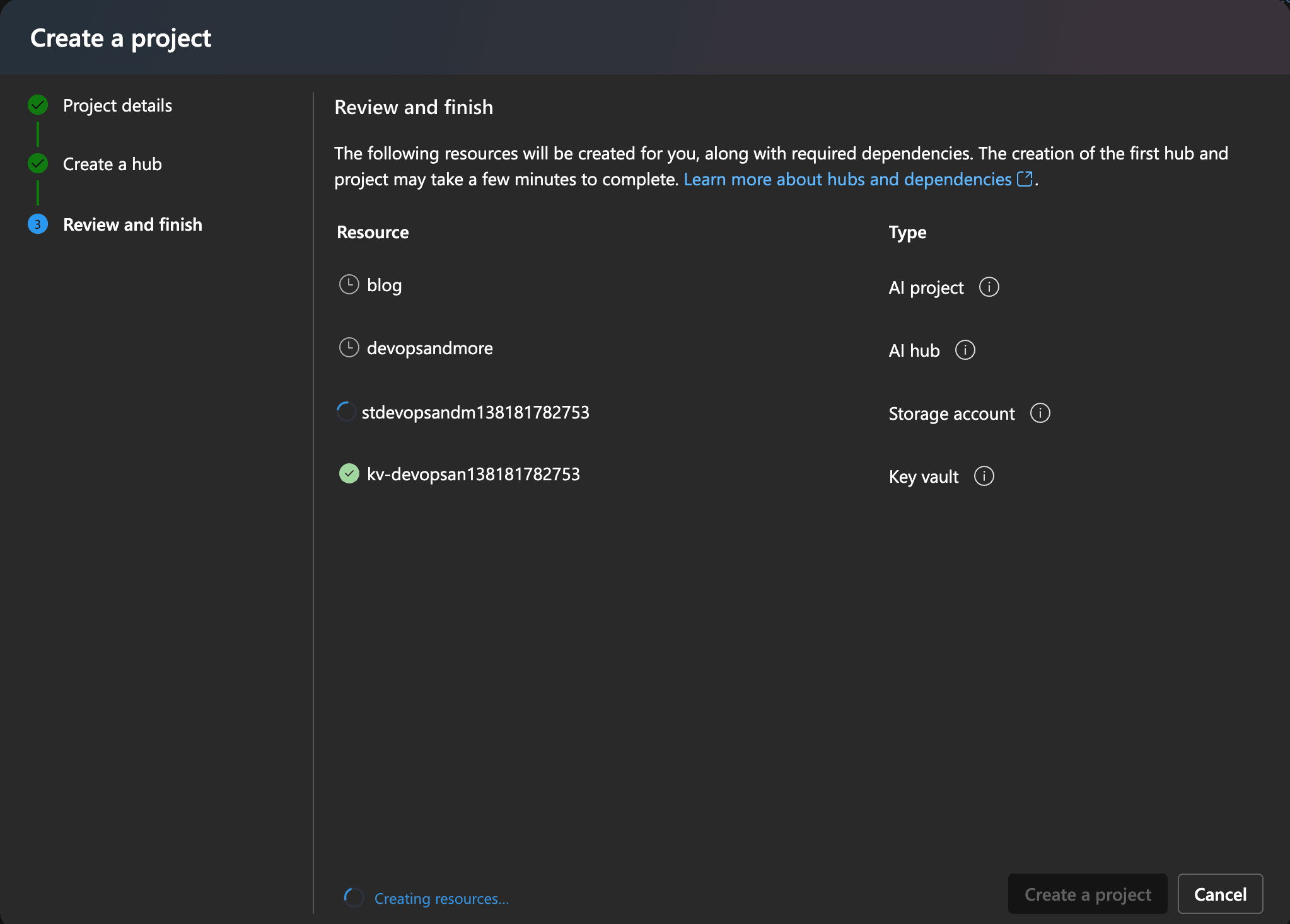 Azure AI Studio - create a project
Azure AI Studio - create a projectNote: Make sure to note step 9: "Select an existing Azure AI services resource (including Azure OpenAI) from the dropdown or create a new one." You need to connect an Azure OpenAI service to your project for this tutorial. Either select an existing one or create a new one
You'll also need the Azurel CLI installed on your computer. Run
az loginto authenticate your Azure account. Select the subscription, you want to use. -
Install the Prompt Flow evaluation and azure packages:
-
Head over to the "Settings" - page of your Azure OpenAI Studio project and note down the following information:
- project name
- resource group name
- subscription id
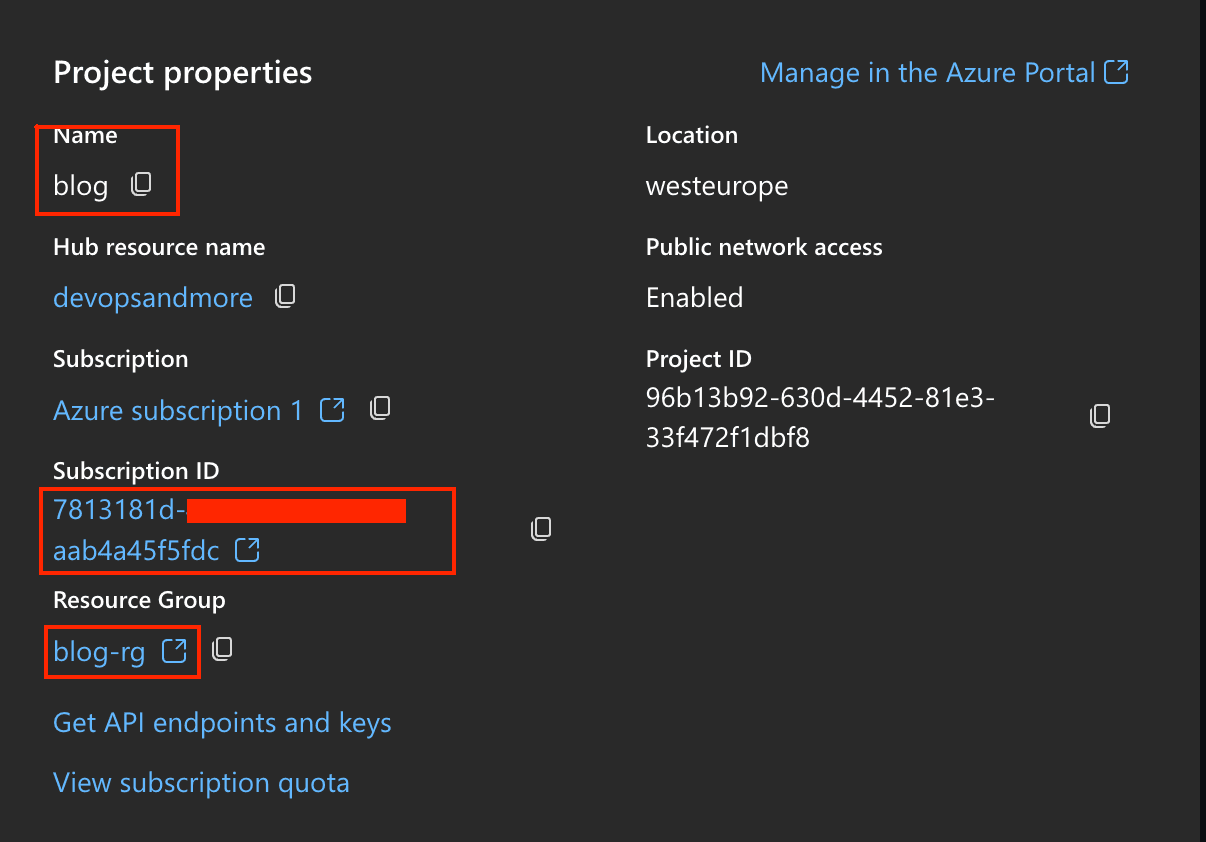 Azure AI Studio - project settings
Azure AI Studio - project settings -
Now we need to create ourselves some AI models to evaluate - and also AI model which acts as "judge" for the evaluation.
This is a critical piece of information: Prompt flow uses an LLM itself to judge the other LLMs. Therefore, it's important to use the best possible model for the evaluation in terms of reasoning quality. Otherwise, the lacking quality of the judge model might influence the evaluation results.
Click on "Model catalog" in the Azure AI Studio left hand side menu. Then, select "GPT-4o".
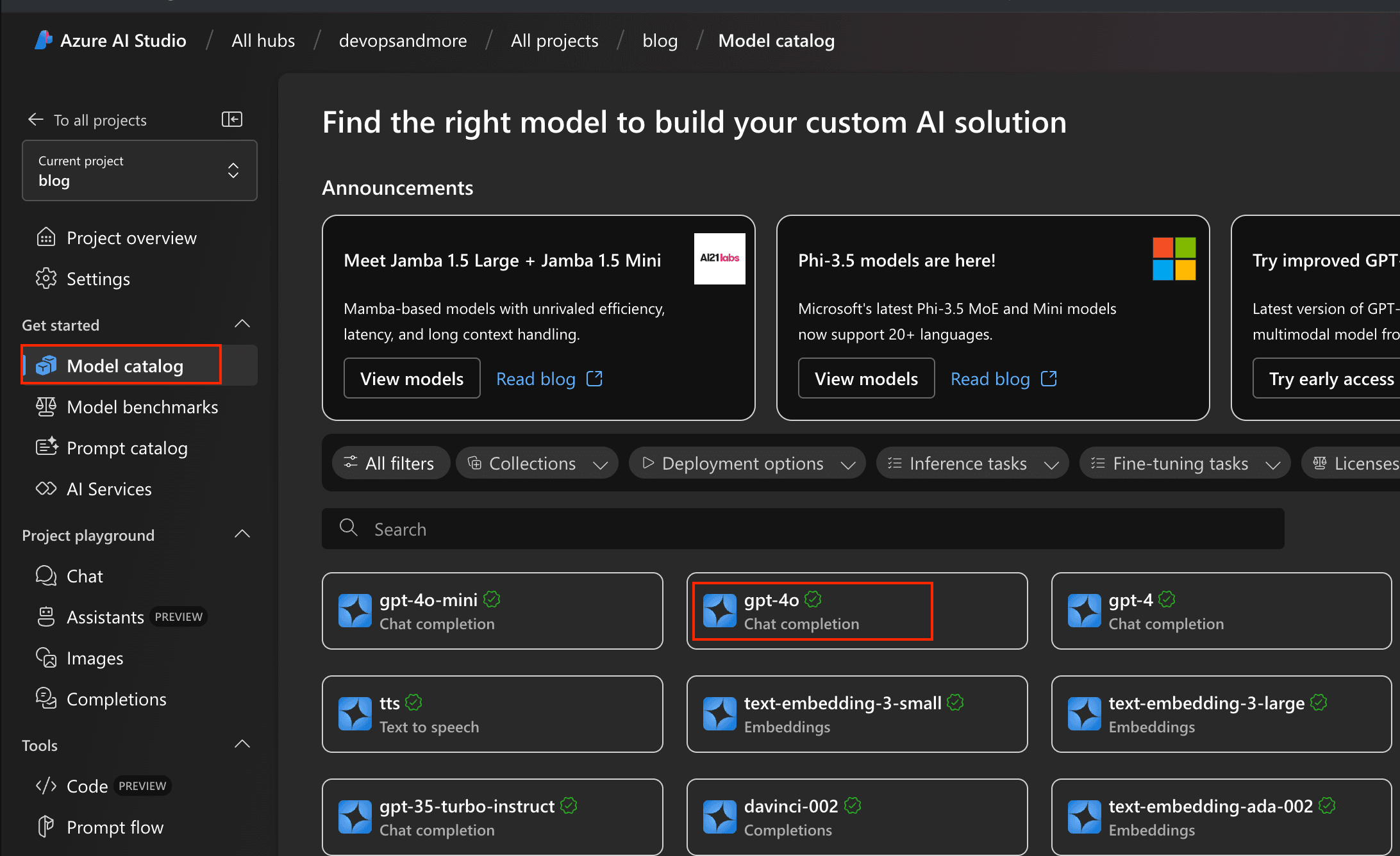 Azure AI Studio - model catalog
Azure AI Studio - model catalogIn the next screen, click on "Deploy" - a modal will open. In this modal, set the options as you see fit. For GPT-4o, the following settings work well, as of time of this writing. In the "Connected Azure OpenAI service" dropdown, select the service you connected or created in step 1 (during project creation).
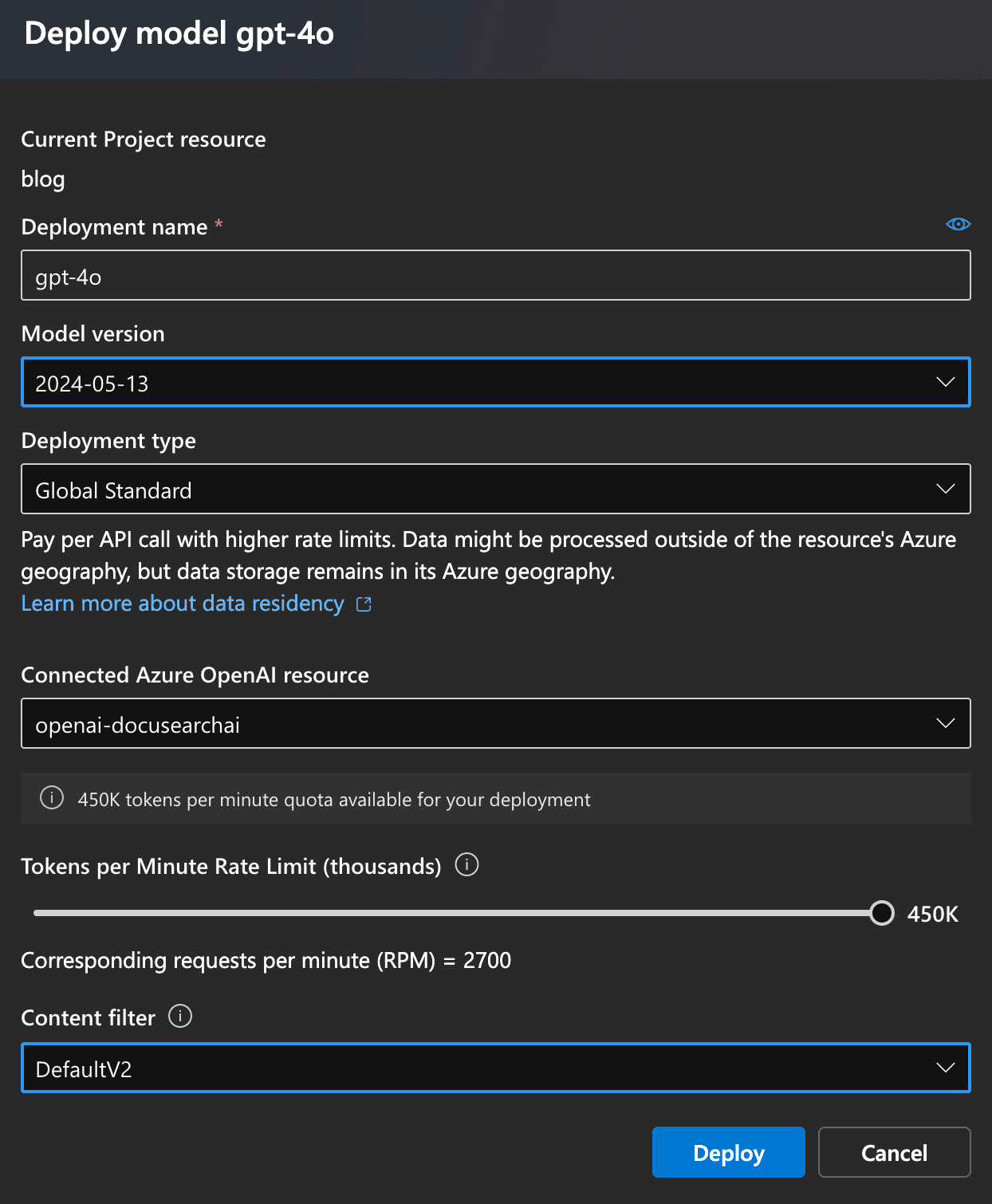 Azure AI Studio - deploy model
Azure AI Studio - deploy modelHit "Deploy" to get the model provisioned.
Note: This model will act as judge for the evaluation. If you just want to follow along this tutorial and don't have a 'real' model you want to validate yet, repeat the steps above and deploy just another model - eg. GPT-35-TURBO
-
Click on "Deployment" in the side bar menu and select the model you just created. In the following screen, you get an overview about the deployed model. Most important for us at the moment is the "Endpoints" section. Note down both the endpoint URL as well as the endpoint key.
-
Next, let's create our model configurations in python. Create an object for the Azure AI project as follows, and use the credentials from step 3.
Then create a model configuration object for the judge model as follows. We need the azure_endpoint, the api_key, api_version and azure_deployment.
To get these information, we can use the information from step 5.
The api_key is simply the endpoint key from the deployment screen.
For the other values, we can deconstruct the endpoint URL as follows: The endpoint URL is structured as follows:
https://<deployment>.openai.azure.com/openai/deployments/<model_name>/<model_type>?api-version=<api_version>Example:https://openai-docusearch.openai.azure.com/openai/deployments/gpt-4o/chat/completions?api-version=2023-03-15-previewFor the example above, the values would be:
- azure_endpoint:
https://openai-docusearch.openai.azure.com - api_version:
2023-03-15-preview - azure_deployment:
gpt-4o
Finally we need to define the model endpoints of the models we want to evaluate. For each model you want to evaluate, we need two information:
- The model api endpoint
- The api key
If the models are deployed in Azure AI Studio, simply use the endpoint and api key from the deployment screen. For other api providers, please refer to the respective documentation.
- azure_endpoint:
Azure permissions for Prompt Flow
While it's not in the official documentation, Prompt Flow uploads your code, the sample data as well as the evaluation results to an Azure blob storage account which is automatically created when creating the project.
Also when provisioning the Azure AI Studio project, a service principal is
created, with the same name as the project - blog in our example.
This service principal is then used to access the blob storage for file upload. By default it seems that it misses a critical permission/role, resulting in the following error:
If this error occurs, follow these steps:
-
Navigate to "Settings" in the Azure AI Studio project and select the "workspaceartifactstore" resource.
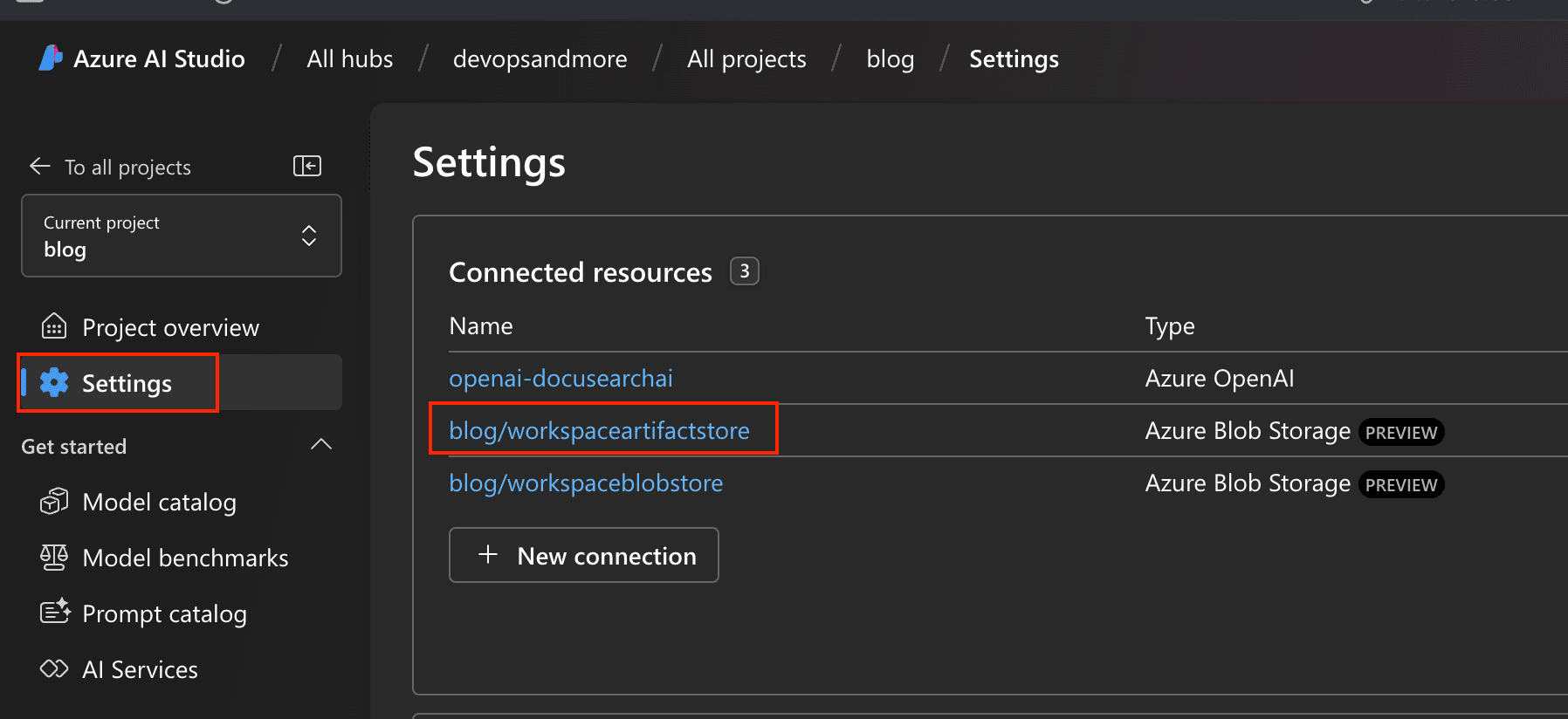 Azure AI Studio - workspaceartifactstore
Azure AI Studio - workspaceartifactstore -
In the next screen click on "View in Azure Portal". There, click on "Access control (IAM)", "Role Assignments" and then "Add".
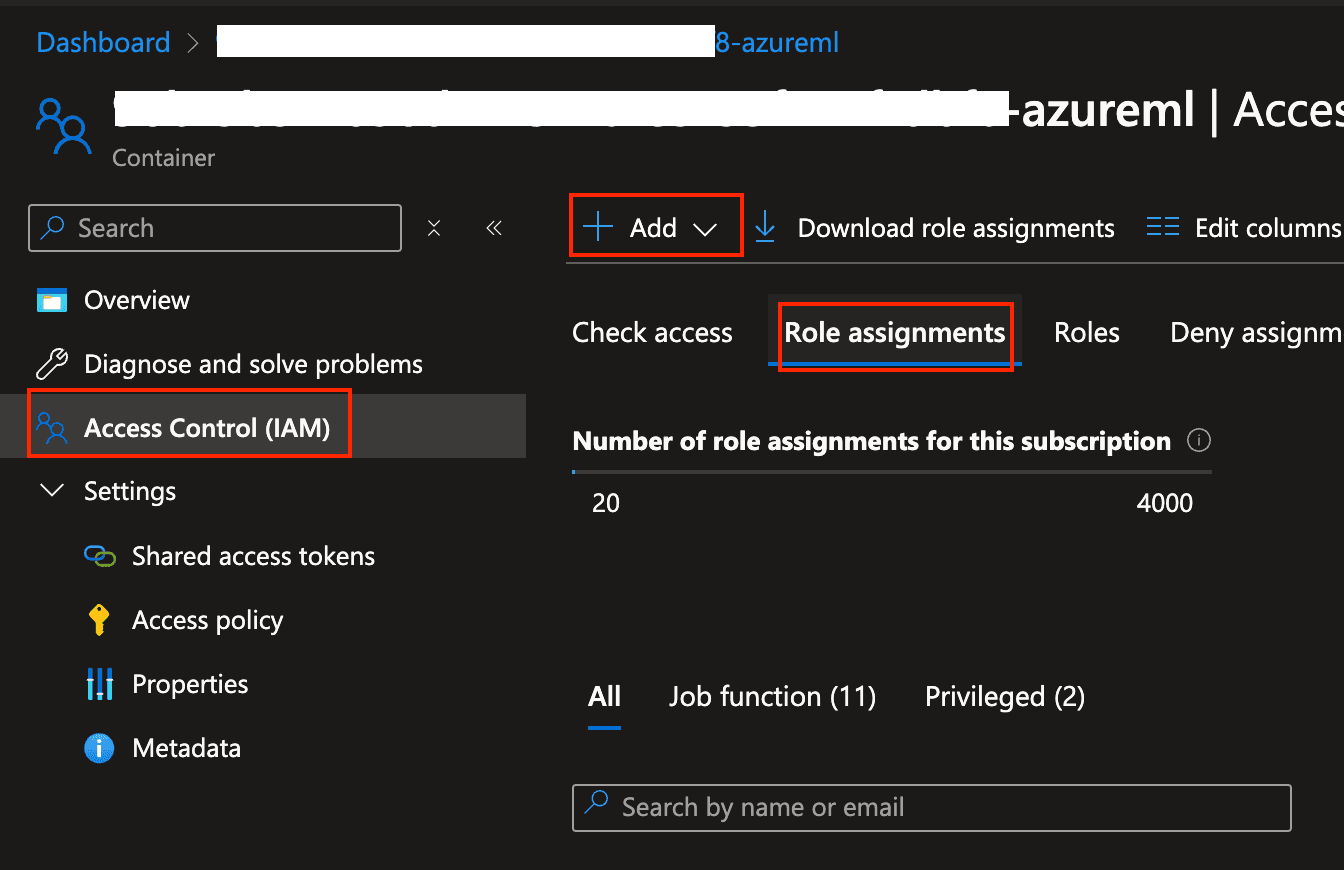 Azure AI Studio - view in Azure Portal
Azure AI Studio - view in Azure Portal -
In the "Role" - tab, select "Storage Blob Data Contributor", then click on the "Members" tab.
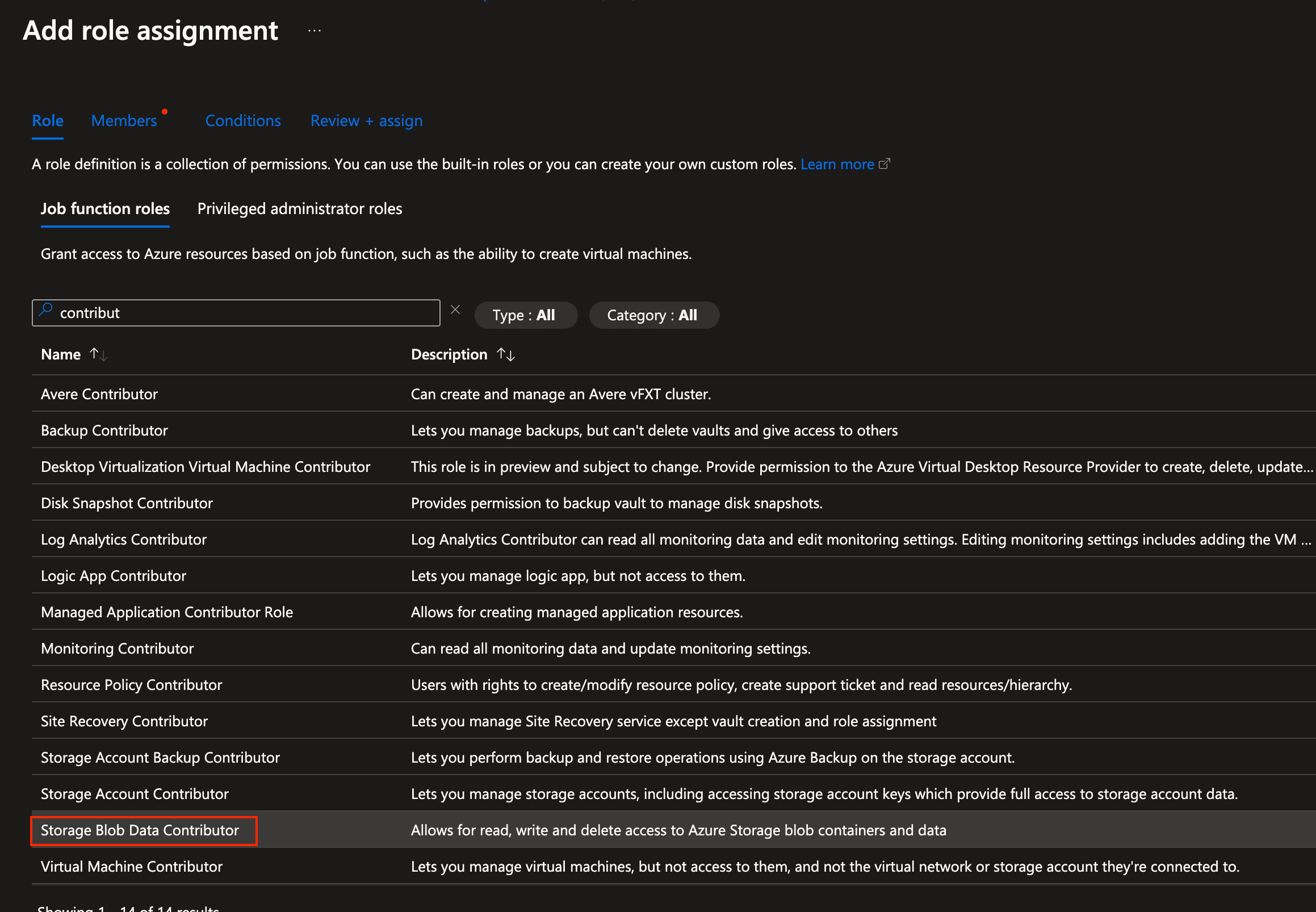 Azure AI Studio - role assignment
Azure AI Studio - role assignment -
Select "Managed Identity", click on "Select members". In the now opening sidebar, select "Azure AI Project" in the managed identity dropdown. Then select the service principal with the same name as the project.
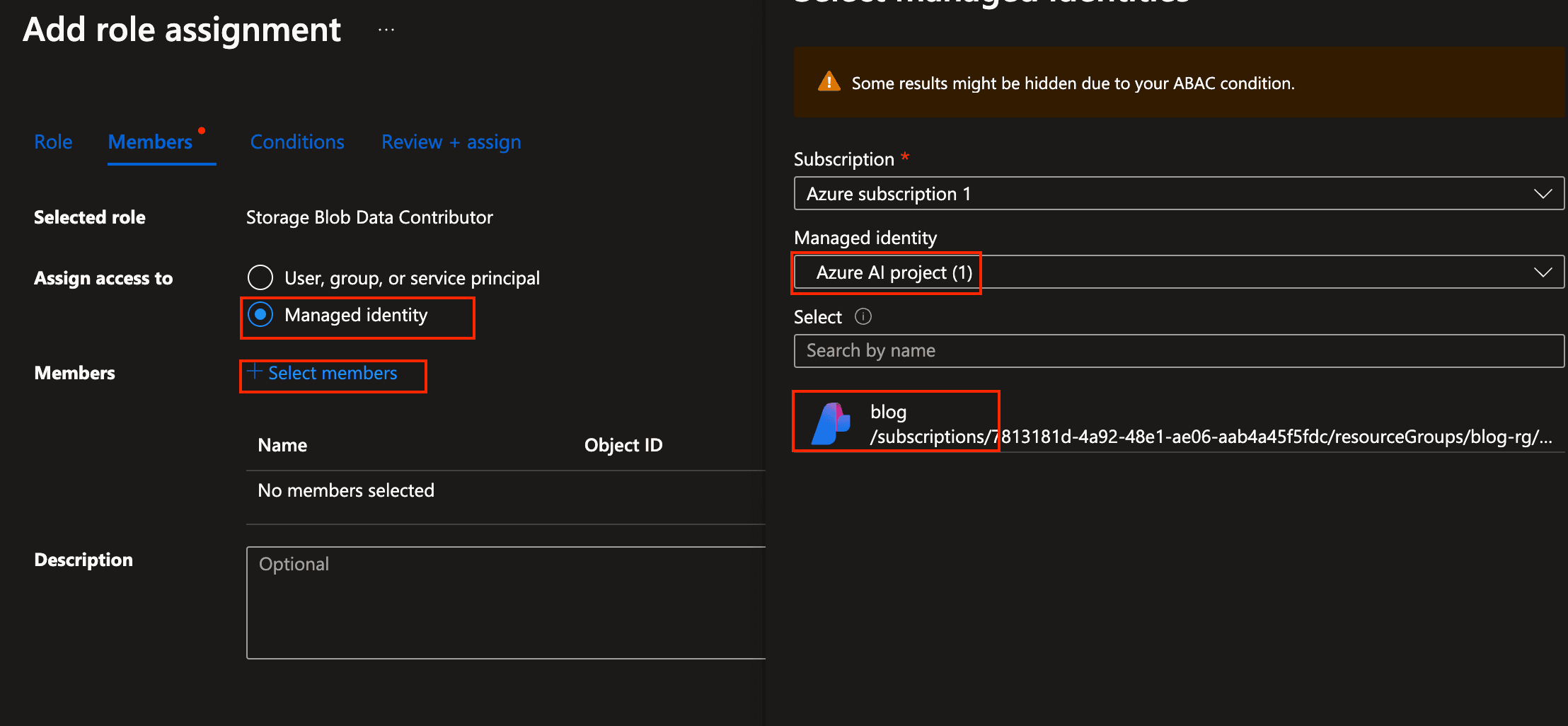 Azure AI Studio - select members
Azure AI Studio - select members -
Click "Select" and then "Review + assign".
That's it, your permissions should now be set.
Creating the evaluation dataset for Prompt Flow
Now that we have all the necessary information, we can create the evaluation dataset. As always with evaluating AI systems, the most important part in the whole process is exactly this, the evaluation dataset.
For Prompt Flow, we need to create a JSONL file with the following
information:
question: The reference question for the modelcontext: Context for the model to answer the question uponground_truth: The correct answer to the question
There is not really a shortcut here. For a good evaluation, you need to invest the time to first create good question/answer pairs.
For this example, we'll use a simple evaluation dataset kindly provided by the Prompt Flow SDK
Create a file named data.jsonl and paste the content above into it.
Creating the model router
Prompt Flow allows to define a target - a callable python class which
basically takes all the evaluation questions and routes them to the respective
model endpoints. This process is actually quite useful, as with that, you
not only can evaluate different models, but also full RAG
pipelines.
The target class call method needs to take a question and conetxt
parameter and return a dictionary with question and answer keys.
Instead of creating a callable class, one can also create a python
function with the question and context parameters and return a
dictionary with question and answer keys. A class however might
provide more flexibility
Add this class to a separate file named target.py:
Some things to note here:
-
Please note the
@tracedecorator. Traces in Prompt Flow record specific events or the state of an application during execution. It can include data about function calls, variable values, system events and more. See here for more information about tracing. -
Our call_gpt4o_endpoint and call_gpt35_turbo_endpoint methods are basically the same and could be implemented using just one function. I provided them here as an example for how one could implement a different API provider.
-
The implementation of the call-endpoint functions can be further extended, depending on your specific application. You can even add a full RAG retrieval pipeline here.
Running the evaluation
We are almost there. All that's left is to define the evaluations we'd like to run and then run them.
-
Define the evaluators. For a list of available evaluators see here. You can also create your own evaluators.
-
Next, create the evaluation configuration.
To view the results, simply print them. Or - for better readability - transform them into a pandas dataframe.
Analyzing Prompt Flow results in Azure AI Studio
As we provided an (optional) Azure AI Studio project configuration, we can use it, to view the results and some nice graphs around the Prompt Flow evaluations.
In Azure AI Studio, select "Tools -> Evaluations" from the left hand side menu. You can find all your model evaluation runs show up here if you’ve logged the results to your project in the SDK.
-
After selecting the Evaluations - menu, Click on "Switch to Dashboard" on the top-right corner - as this gives a better overview for comparing runs.
-
After that, you can select one or many 'runs' to compare. Each model we defined in our code above will show up as separate run. Let's select both, our GPT-4o and GPT-35-TURBO runs. As you can see in the screenshot below, this gives a very nice comparison of all the metrics we defined. In our example, GPT-4o seems to be the better model in almost any regards (which is not too surprising.)
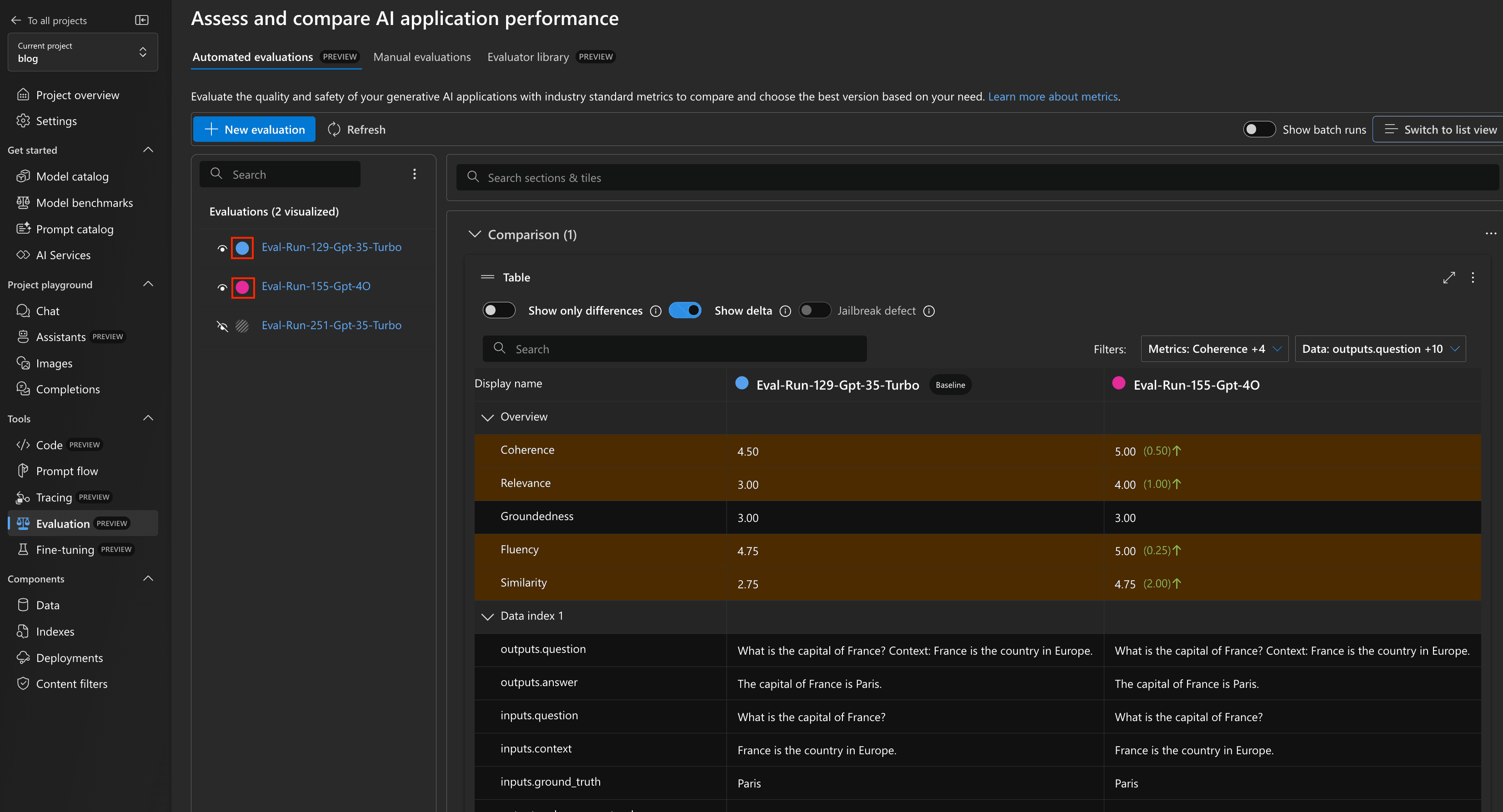 Azure AI Studio - evaluation dashboard
Azure AI Studio - evaluation dashboardIf you scroll down, you get detailed comparisons of the individual answers of each run.
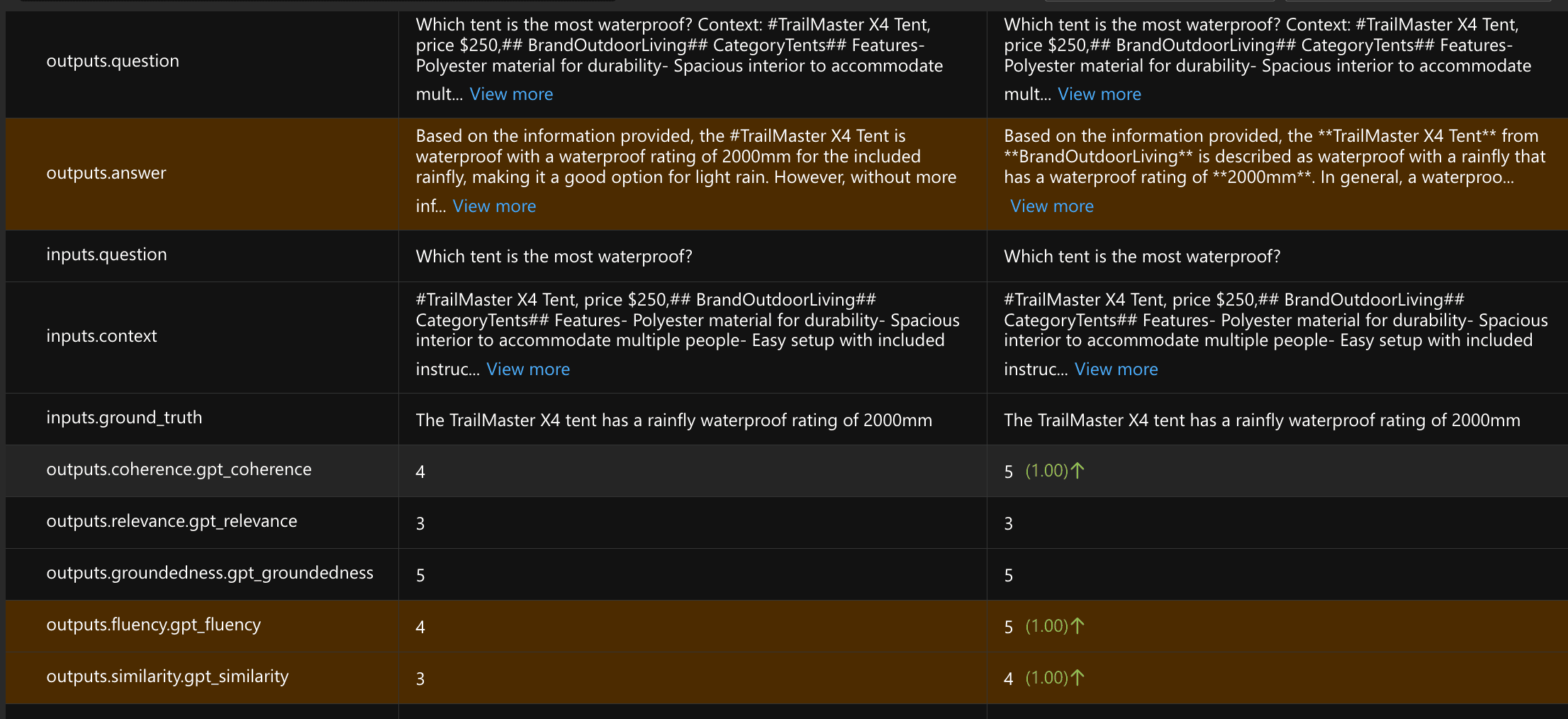 Azure AI Studio - evaluation details
Azure AI Studio - evaluation details -
Additionally to comparing two or more runs, you can open the individual runs and get detailed evaluation results for each individual run. You'll get nice charts of each metric as well as again the detailed questions and answer as well as grades per answer of each individual evaluation.
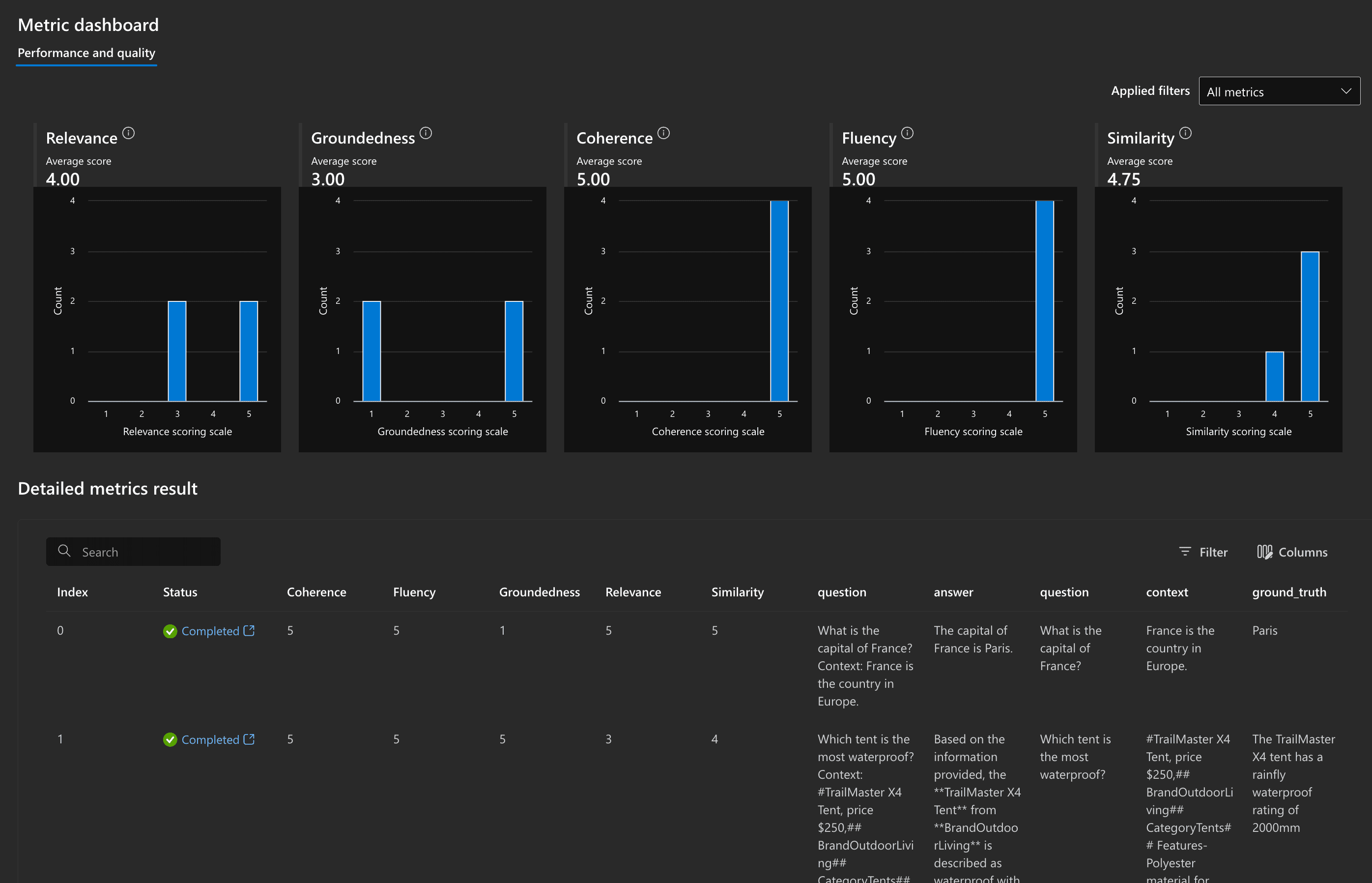 Azure AI Studio - individual run evaluations
Azure AI Studio - individual run evaluations
So, that's it. Quite a few steps, but in the end this is quite a powerful setup for you to evaluate models before upgrading. Simply add a new model to the model endpoints, and you can evaluate it against your existing baseline model.
Using Prompt Flow without Azure AI Studio
If you want to use Prompt Flow without Azure AI Studio, you can do so.
Basically, the way to go is exactly as described above, just without having the lines of code which refer to Azure AI Studio. For brevity, find the code for evaluating models without Azure AI Studio below.
Further reading
- How to fine-tune GPT-4o mini (for free until September 2024)
- Chat with your confluence using LLMs
- Need a privacy-friendly ChatGPT alternative?
Interested in building high-quality AI agent systems?
We prepared a comprehensive guide based on cutting-edge research for how to build robust, reliable AI agent systems that actually work in production. This guide covers:
- Understanding the 14 systematic failure modes in multi-agent systems
- Evidence-based best practices for agent design
- Structured communication protocols and verification mechanisms