RAG, Embeddings and Vector Search with Google BigQuery

Google BigQuery is a phenomenal Data Warehouse. With it's serverless architecture and Googles first-class scaling capabilities, it's a great choice for storing and querying large datasets.
At the same time, more recently vector databases were all the rage as you need them to implement semantic search. Our take on vector databases is, that they are great, but you certainly only need a specialized database for vectors if you don't already have a database at all. If you already have any sort of database in use, just use the vector extensions of them - almost any database provides them. Postgres has pgvector, CrateDB has vector support, Elastic Search as well and even DuckDB has them.
But what about BigQuery? Obviously Google couldn't just sit still and watch, so they naturally added vector support as well.
That's what we are going to look at today. We will demonstrate the vector data type, show how create vectors from your texts and how to query them.
One very neat feature of BigQuery is, that you can use AI models directly from your database, without needing additional infrastructure. Very similar to what Timescale created with their pgai extension for postgres. We'll also show how to use that feature.
Preparation: Install the required dependencies
Preparation: Creating a table in BigQuery with sample text data
First things first, let's create ourselves a dataset which we can use for this demo.
-
Download our demo pdf document from our website
-
Use LangChain to extract the text from the pdf and chunk it into smaller pieces. After this, we have chunks of texts with ~1500 characters each. Each chunk will represent a row in BigQuery.
-
Next, with your browser, navigate to the Google BigQuery console and create an empty dataset and table.
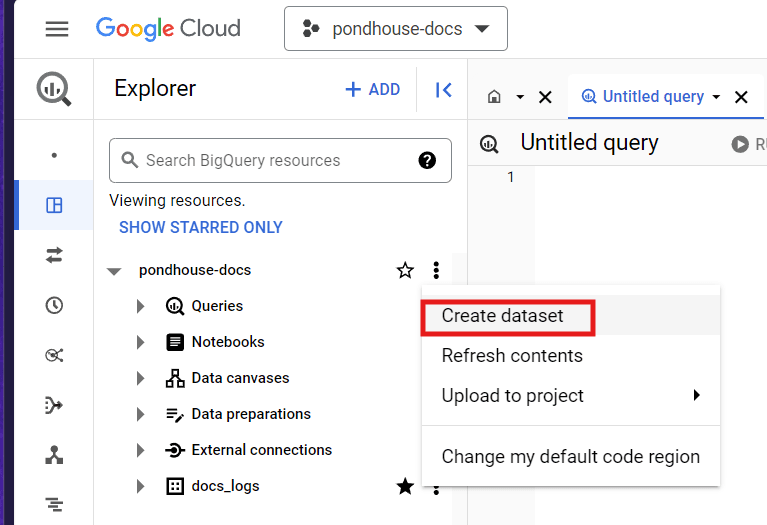 Create a new dataset
Create a new datasetGive your dataset a name, select the region you want to deploy the dataset to and click "Create Dataset".
-
Now, we only want to add a timestamp and the text for now, the embeddings will be added later on. To do, we reformat our documents and save them as csv.
-
In this newly created BigQuery dataset, add a new table:
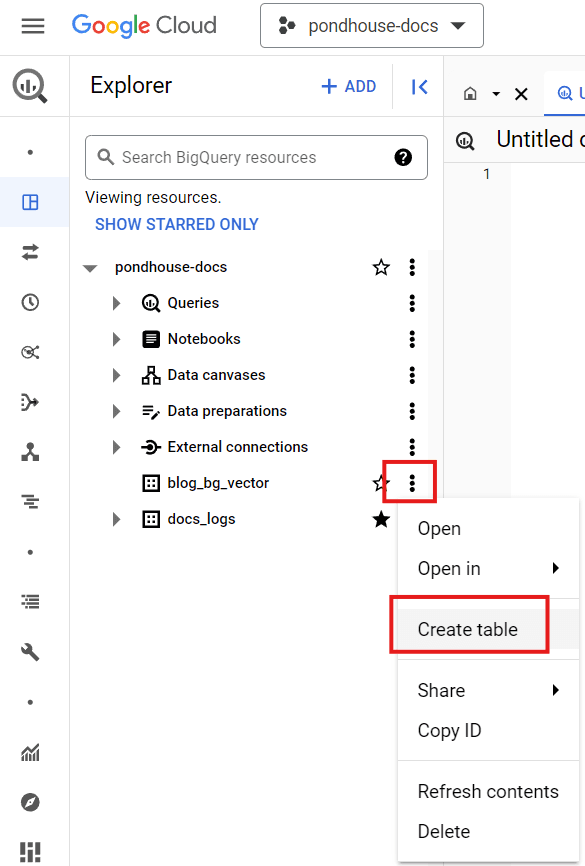 Create a new table
Create a new tableFor the table, select "Upload" in the "Create table from" give it a name, and add the following columns in the "Schema" section:
- timestamp:
TIMESTAMP - text:
STRING
 Table setting
Table settingIn the "Select file" section, upload the csv file you created in the previous step.
Optionally, set partitioning and clustering as for any other BigQuery table.
In the "Advanced options" section, make sure to select "Quoted newlines", otherwise line breaks in your text will break the import.
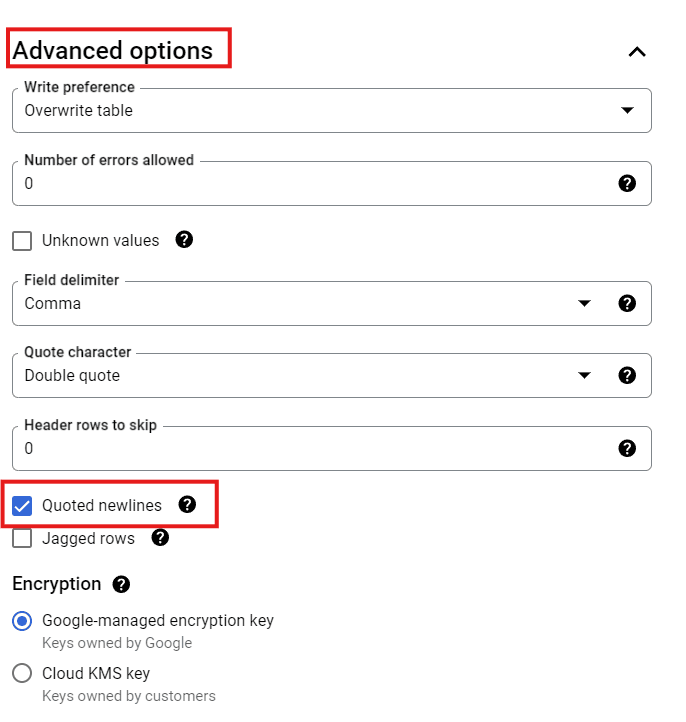 Table advanced options
Table advanced optionsClick on "Create Table" to finish the process. This will upload the csv file and insert the data into the table.
Note: The BigQuery csv upload is quite sensitive. Make sure, youre csv file does not contain headers and that your csv file uses the "quote all" option as shown above.
Navigate to the "Preview" tab of the table to check if the import was successful.
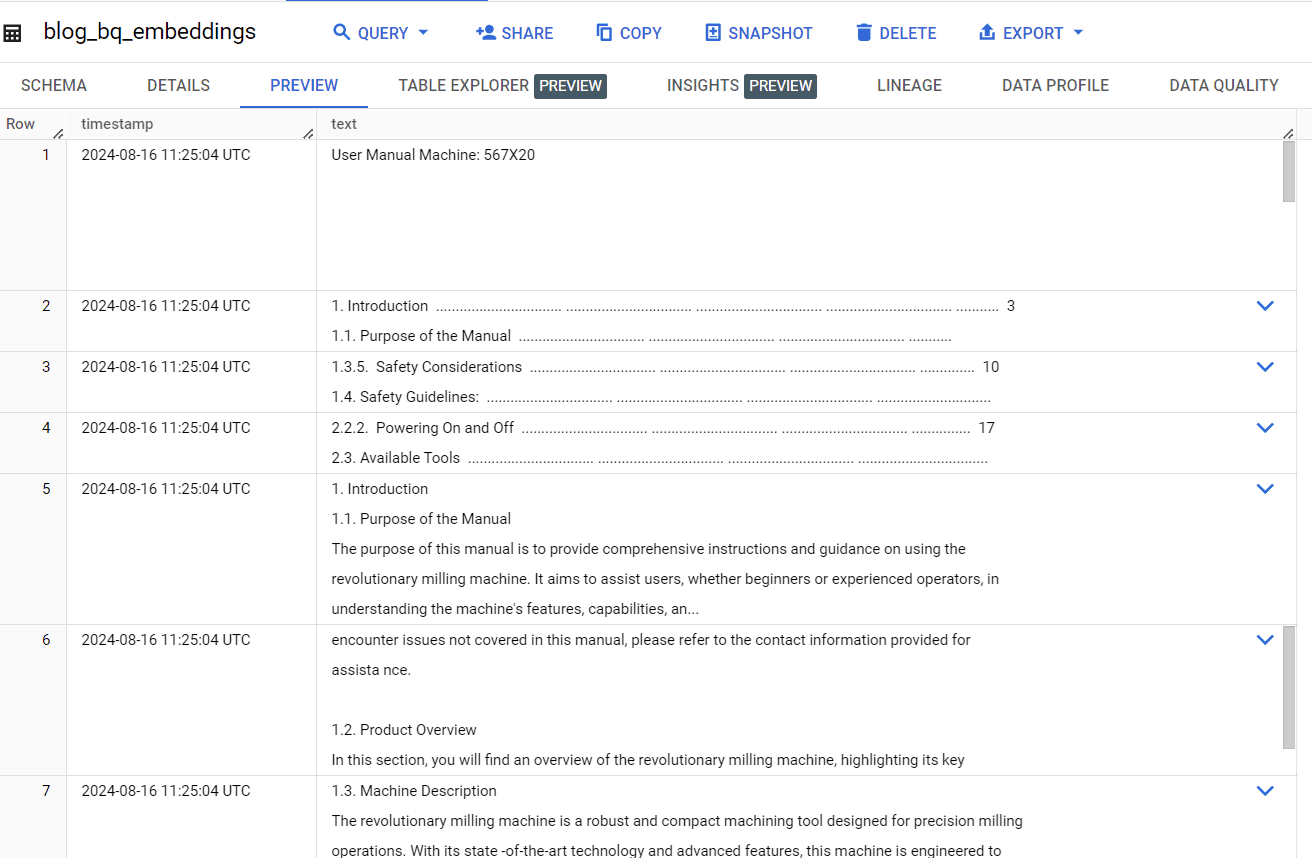 Preview imported data
Preview imported data - timestamp:
-
Now that we have our data in BigQuery, let's add an empty column for the embeddings. Embeddings in BigQuery are stored as simple float arrays.
That's the important part: embeddings in BigQuery are simply stored as an array of floats. This makes them also quite versatile, as you are not limited to a specific vector size.
In the "Schema" tab, click on "Edit Schema" and add a "REPEATED" "FLOAT" column called "embeddings", as shown below:
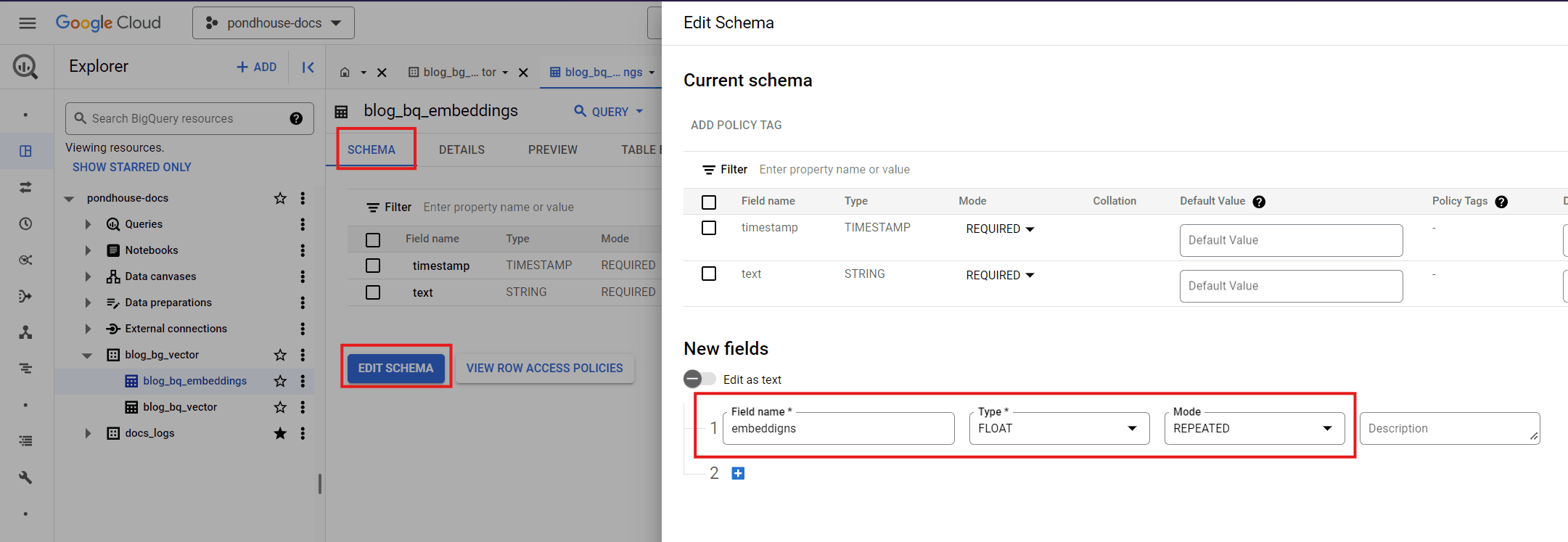 Add embeddings column
Add embeddings column
Preparation: Create BigQuery connection to remote AI models
Now that we have some data available, we want to create embeddings.
Note that you could simply use any embedding model - eg. the OpenAI
embedding models - to
create the vectors and insert them into the embeddings column.
However, we're going to use a more convention method - we'll use BigQuery
ML to use
an embedding model right from our BigQuery console using just plain SQL.
BigQuery currently allows the following embedding models to be used:
- The Google Generative AI embedding models
- Pretrained tensorflow models NNLM, SWIVEL and BERT
As for most cases, the LLM-based approaches provide better quality and are easier to use, we'll stick with them.
-
In your BigQuery console, click the "+Add" button on the top-left. Then click "Connections to external data sources".
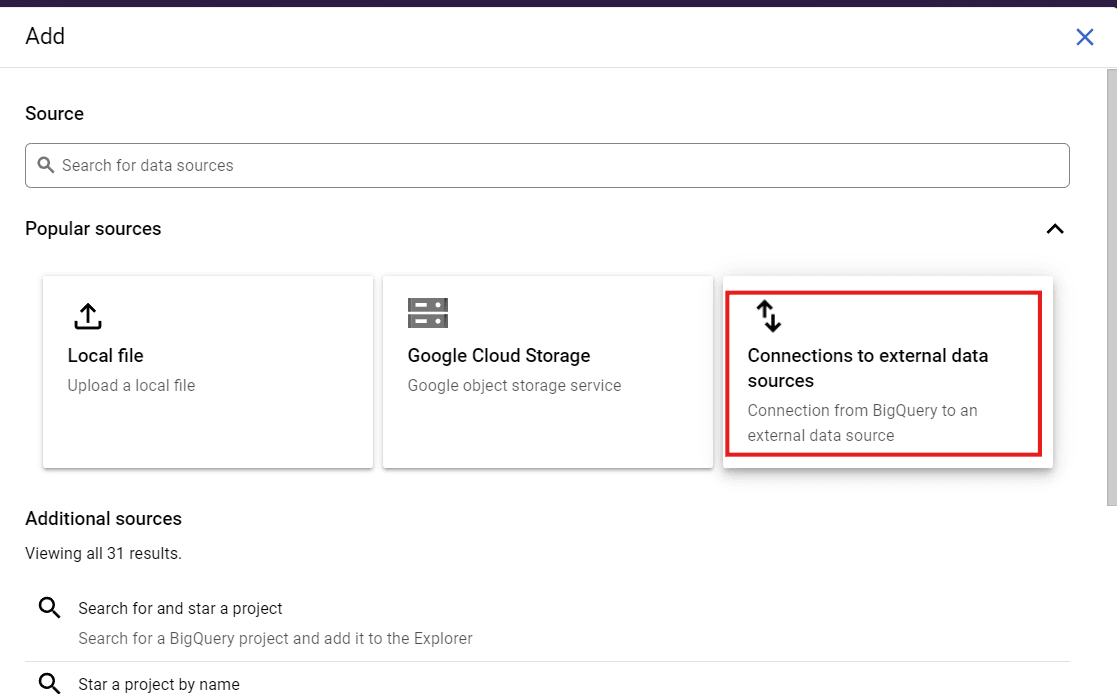 Create external connection
Create external connection -
In the next screen, select "Vertex AI remote models, remote functions and BigLake" as "Connection type". Set a connection id, select your region and click "Create Connection".
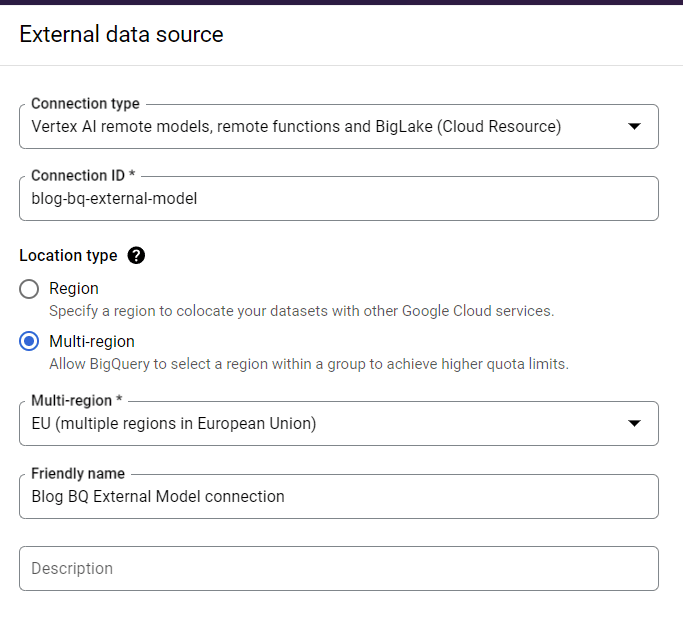 Create connection to a remote model
Create connection to a remote model -
In the grey popup, click on "Go to connection". Note down the service account id for this connection.
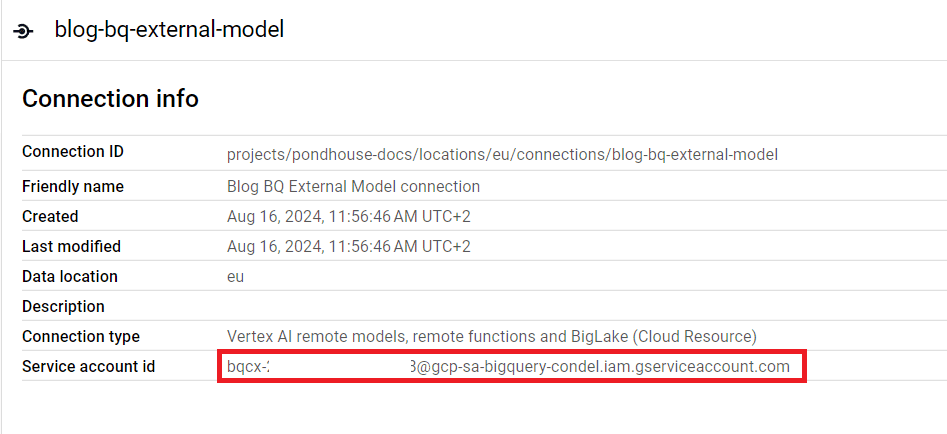 Connection service account id
Connection service account id -
Next, we'll need to equip bespoke service account with some permissions. Go to the IAM page, click "GRANT ACCESS". In the next screen, add the noted down service account id in the "New principals" field and select "Vertex AI User" for the "Role". Click on "Save".
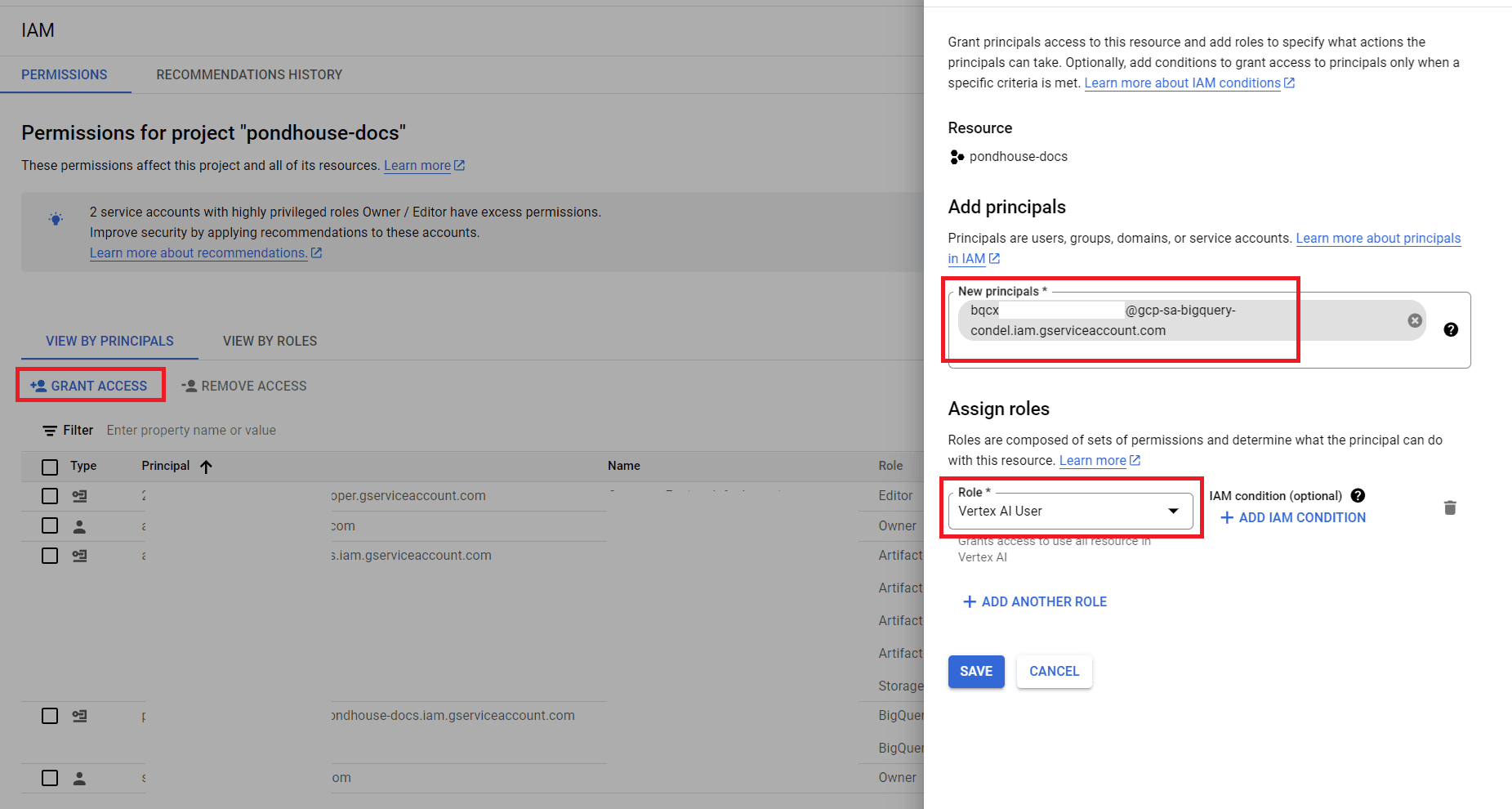 Grant Permissions to service account
Grant Permissions to service account -
Finally, in your BigQuery console, run the following query:
Please change the following terms as for your configuration:
-
blog_bg_vector: Name of the dataset (not table!) -
eu: Name of the location of your external data source connection -
blog-bq-external-model: Name of the external data source connection
Note:
text-embedding-004is the name of the Google embedding model to use.After running this query, the model will be available for use. You can see the created embedding model as a sub-object under your BigQuery dataset:
 Embedding Model in BigQuery console
Embedding Model in BigQuery console -
Create embeddings with BigQuery
Now that we have ourselves an embedding model available, let's add embeddings to the text data we imported.
We can do all of the embedding creation from within the BigQuery console.
The neat thing about BigQuery ML is, that you can interact with models
just by using SQL. In our case, we want to UPDATE the embeddings columns
with our text embeddings. So, let's craft an UPDATE statement doing just that:
Note: ml_generate_embedding_output contains errors if there are any.
An empty ml_generate_embedding_output means no errors. Therefore we are
checking for LENGTH(ml_generate_embedding_status)=0
After running the query, we can check if the embeddings are updated as planned. Navigate to the "Preview" pane of your table.
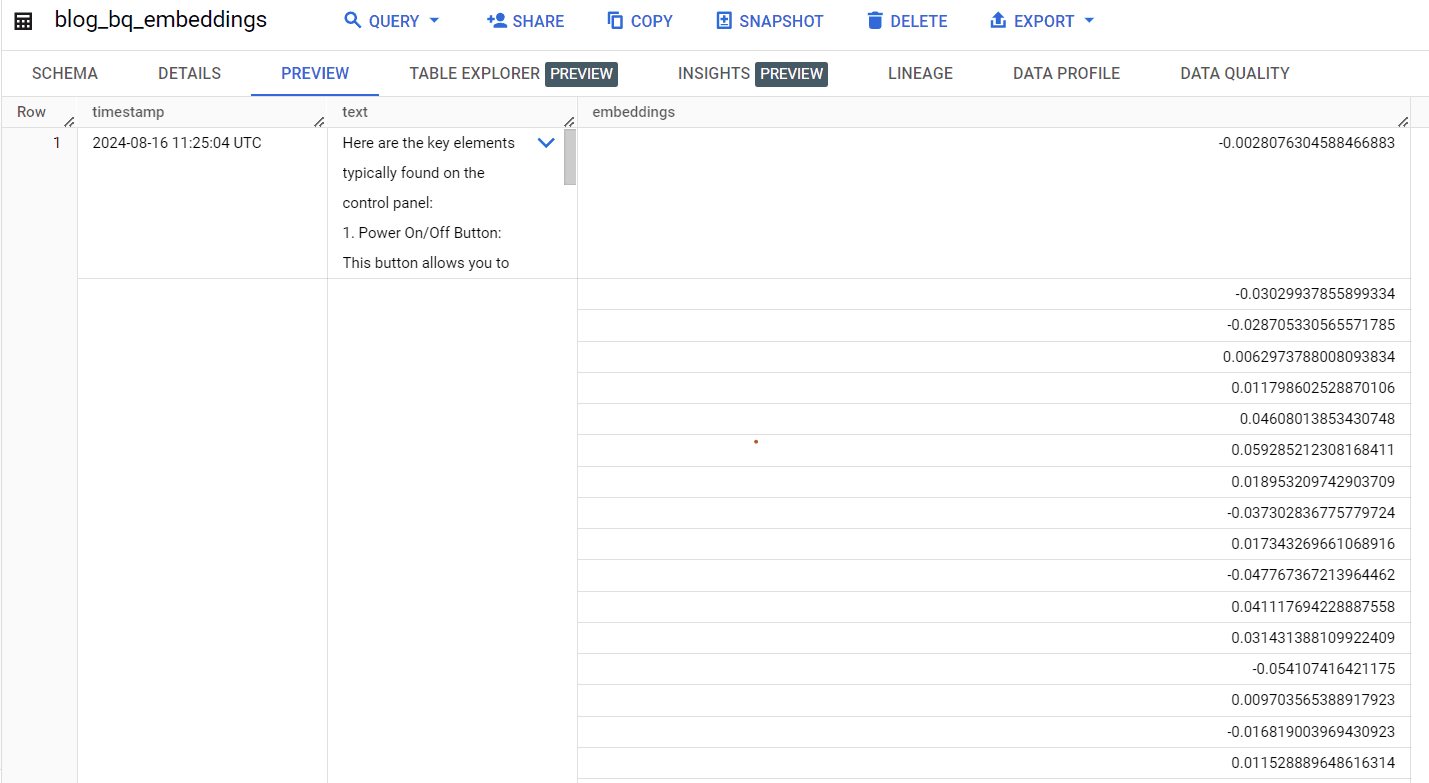 Preview of created embeddings
Preview of created embeddings
Querying embeddings with BigQuery
For the sake of completeness, let's find out, how we can use vector similarity search to find texts which are semantically similar to a search query.
BigQuery provides a function VECTOR_SEARCH
for doing that.
Let's say we want to:
- search for "How to maintain the machine"
- get the 4 most similar docs
- use cosine similarity
our query would look as follows:
Please note that you can easily pre-filter your data by simply adding a WHERE clause to the very first function parameter.
This query will return the text-embedding of the search query, the distance
to each of the individual rows as well as any column included in the
first parameter SELECT statement. So, you not only get the distance
and text of the rows, but any of the metadata accompanying them.
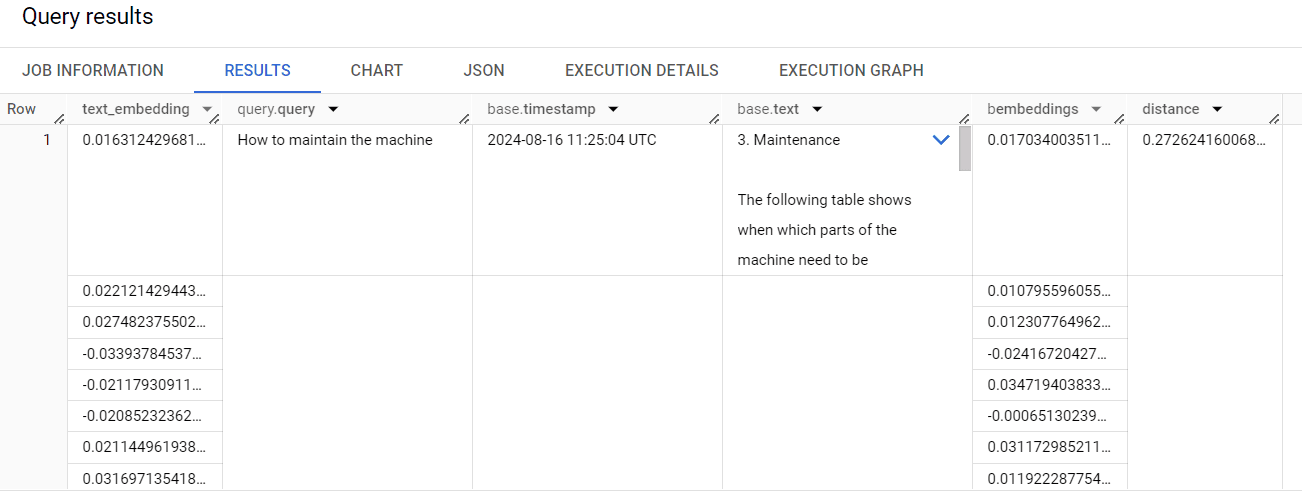 Results of vector search
Results of vector search
Creating a vector search index
The retrieval query above did not use any index, which might be slow in production scenarios.
Therefore, BigQuery offers two types of indexes :
-
IVF Index: IVF is an inverted file index, which uses a k-means algorithm to cluster the vector data, and then partitions the vector data based on those clusters
-
TreeAH Index: TreeAH is a type of vector index that uses Google's ScaNN algorithm.
The ScaNN algorithm is one of the fastest and most efficient search algorithms out there. However, it has one significant drawback: As of time of this writing, TreeAH indexes do not support pre-filtering. So, if you want to filter your data before running the vector search, using a WHERE clause, you are out of luck.
We suggest to use IVF indexes for use cases below 10 Million rows, and TreeAH indexes for larger datasets.
Creating an index once again is just an SQL query away:
The num_lists parameter defines how many lists the IVF algorithm
creates. The IVF algorithm divides the whole data space into a number of
lists equal to num_lists, with data points that are closer to each other
being more likely to be put on the same list. If this is small, you have
fewer lists with more data points, while a larger value creates more lists
with fewer data points.
As a general rule of thumb: If you have many vectors which are rather
similar to each other, you have many larger lists. Set num_lists to a
smaller value. If you have many vectors which are rather different from
each other, you have many smaller lists. Set num_lists to a larger value.
Creating an index might take some time - you can check progress with - you guessed id - another SQL statement:
That being said: BigQuery only allows to create indexes on tables with at least 5000 rows (as for low row counts, the 'brute force' search is faster and/or the index can't be created efficiently). Therefore, if your dataset is smaller than 5000 rows, don't bother with creating an index.
However, if you have more than 5000 rows, make sure to create an index, as this will speed up your queries significantly.
Now that we have our index (or not, if we have too little rows), how to use it during query time? Easy, do not bother at all - BigQuery will automatically use the index if it is available.
Retrieval Augmented Generation with BigQuery
In the introductions above, we've seen how to index our text data, how to retrieve these indexes using vector similarity search and how to add an index to make this whole ordeal fast.
Actually this is almost all we need to implement a simple, but quite powerful Retrieval Augmented Generation (RAG) process - fully on top of BigQuery. Without ever needing to set up additional infrastructure for the indexing and retrieval part of RAG.
Creating a remote text generation model
The only missing part for a RAG pipeline is the "Generation" part - meaning the part were the search results are observed by a text generation LLM and an answer is provided based on these search results.
Similar to how we created a remote embedding model, let's create a remote text generation model.
Make sure to change blog_bg_vector to your dataset
name, as well as eu.blog-bq-external-model to your location
and external connection id, as specified in the chapters above.
The ENDPOINT option defines, which model we want to use. We are currently
big fans of Gemini 1.5 flash
due to its enormously attractive pricing, extremely fast inference and overall
quite good quality.
After the query is done, you have a new remote model available, named
blog_bq_vector.blog_bq_text_model.
Putting all together: Full retrieval augmented generation process with Google BigQuery
Ok, finally we have everything we need. Summarizing, during retrieval in RAG, we:
- Retrieve similar texts as compared to our search query
- Send these similar texts as context to our LLM
- The LLM provides a final answer, based on this context and the search query
Amazingly enough, all 3 points can be implemented using a single SQL statement:
As this query is a little more complex, let's break it down. See the comments in the SQL statement for reference. The statement has to be read from inside to outside. The inner-most parts are executed first.
-
We retrieve similar vectors, using the embedding model. This is literally the same process as described in the chapters above. After this step, we have 5 documents which are semantically similar to our user query, which is
How to maintain the machine?.We set the following options:
-
top_k: Sets the number of similar documents we want to retrieve, ordered by most similar. -
distance_type: Type of vector search to use. -
fraction_lists_to_search: Number between 0 and 1. Defines, the percentage of index lists to search. Specifying a higher percentage leads to higher recall and slower performance, and vice versa.
-
-
Next, we create a prompt from our retrieved documents. For that, we use the BigQuery SQL functions STRING_AGG, which simply combines all the string values of the returned rows and separates them by
\n- and the CONCAT, which simply concatenates strings together. -
And last but not least, we use the
ML.GENERATE_TEXTfunction to talk with our LLM. Under the hood, the prompt is sent to the LLM, and an answer is provided asml_generate_text_llm_result, which we rename togenerated. Additionally, the prompt is returned as well - which is nice to debug our models answer.We set the following options:
-
max_output_tokens: How many answer tokens should the LLM provide? Important for cost control -
flatten_json_output: if set true returns a flat understandable text extracted from the LLM response. Recommended to set to true.
-
After running the query, we get these results:
 BigQuery RAG results
BigQuery RAG results
To be honest, this looks very very promising. Even though the SQL query above looks a bit convoluted - we just implemented a basic RAG pipeline with 30 lines of code or so - without needing any additional infrastructure!
Pricing considerations
As a final note, let's talk pricing. There are multiple components defining the final price:
-
The good news: There is no additional costs for the index creation. Only for the index storage itself, which is priced by bytes stored for the normal BigQuery storage rates
-
You pay for any BigQuery query, as per the normal BigQuery analytics pricing
-
You pay for each AI invocation. The pricing for the AI models is as follows:
-
Embedding model: Google Vertex AI pricing 0.000025$ per 1000 characters
-
Gemini 1.5 Flash Text generation model: Google Vertex AI pricing 0.00001875$ per 1000 characters
-
So, what's the real cost? As always with BigQuery it's hard to tell upfront. Best is to navigate to the "Details" tab of your BigQuery table to see the current storage costs, and use the query run estimation in the BigQuery console for analytics costs.
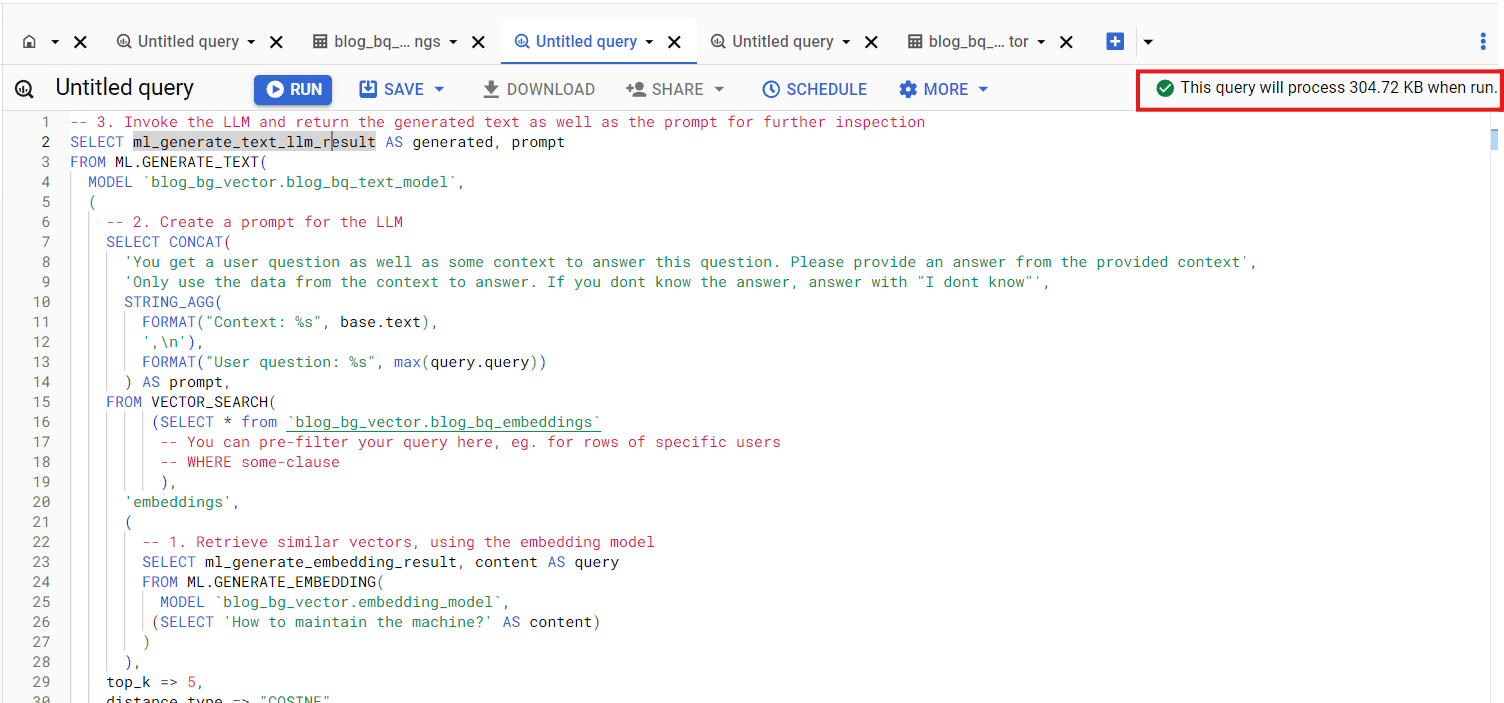 BigQuery analytics cost estimate
BigQuery analytics cost estimate
Note: While it's always a hassle to calculate actual BigQuery costs, the vector search pricing as well as the AI model pricing is highly competitive. According to our experience, the total costs are remarkably low.
Conclusion
To wrap up, Google's addition of vector support to BigQuery bridges the gap between traditional data warehousing and modern AI-driven applications. By embedding, indexing, and querying vectors directly within BigQuery, you can streamline complex workflows and eliminate the need for separate, specialized infrastructure.
This approach enables us to use AI tools, such as embedding models and LLMs, directly through SQL, making advanced capabilities more accessible within our existing data ecosystem.
Moreover, the competitive pricing structure ensures that even as you scale, costs remain predictable and manageable. BigQuery's vector capabilities provide a solid foundation for integrating AI into any data operation, making it a valuable asset for organizations looking to tap their feet into AI applications.
Further Reading
- Using AI directly from your PostgreSQL database
- Create knowledge graphs using Neo4j LLM knowledge graph builder
- Use GPT-4o to parse pdf, docx and xlsx
Interested in building high-quality AI agent systems?
We prepared a comprehensive guide based on cutting-edge research for how to build robust, reliable AI agent systems that actually work in production. This guide covers:
- Understanding the 14 systematic failure modes in multi-agent systems
- Evidence-based best practices for agent design
- Structured communication protocols and verification mechanisms