GenAI: Technological Masterpiece or Ecological Disaster?

The origins of generative AI, or GenAI, go back several decades. However, these highly technical approaches were long accessible only to specialized expert circles. Over the last two years, this situation has dramatically changed. The launch of ChatGPT in the fall of 2022 marked the beginning of a new commercial sector. OpenAI has succeeded with GPT-3 and ChatGPT in developing a highly efficient model that exhibits deep semantic understanding, multilingual capabilities, and high accuracy, now made widely available as a "ready to use" product. Progress has not only been made on the text generation side. With diffusion models like DALL-E, Midjourney, and Stable Diffusion, innovative image-generating models have been created that deliver astonishing results.
In less than two years, ChatGPT and similar technologies have not only achieved a high level of recognition (ChatGPT: 1.8 billion visits in March 2024) - they continue to impress with their capabilities and have already changed the way we work in some areas. These technological advances are here to stay and will continue to impact our work methods.
Trend
The desire for ever better and more accurate results has sparked an intense competition and race for more powerful models. This has led to increasingly larger amounts of data being used to train ever larger models. While about 0.5 trillion tokens were used for a model with 175 billion parameters for GPT-3 in 2020, the data volume for GPT-4 is estimated to be around 13 trillion tokens for an MoE model with (rumored) 16x111 billion parameters. Unfortunately, OpenAI does not release official figures for this. Even for models whose data is known – such as Llama2 with 2 trillion tokens and up to 70 billion parameters; Palm2 with 3.6 trillion tokens and 340 billion parameters – the dimensions have significantly increased.
It is impressive how much progress has been made in such a short time and what the current models are capable of both in text and image generation. However, this race also has its downsides.
Carbon Footprint
These extremely large models require immense resources to cover the necessary computational capacities. These processes are highly computationally intensive both during training and during inference, the actual use of the model. According to the International Energy Agency (IEA), data centers were responsible for about 2% of global electricity usage in 2022. Of this, 40% of the power requirement is for computing, 20% for associated IT equipment, and another 40% solely for cooling.
The forecast by the IEA is even more dramatic. They estimate that "Electricity consumption from data centres, artificial intelligence (AI) and the cryptocurrency sector could double by 2026. Data centres are significant drivers of growth in electricity demand in many regions. After globally consuming an estimated 460 terawatt-hours (TWh) in 2022, data centres’ total electricity consumption could reach more than 1 000 TWh in 2026. This demand is roughly equivalent to the electricity consumption of Japan."
They also note in their report that "Future trends of the data centre sector are complex to navigate, as technological advancements and digital services evolve rapidly. Depending on the pace of deployment, range of efficiency improvements as well as artificial intelligence and cryptocurrency trends, we expect global electricity consumption of data centres, cryptocurrencies and artificial intelligence to range between 620-1050 TWh in 2026, with our base case for demand at just over 800 TWh – up from 460 TWh in 2022. This corresponds to an additional 160 TWh up to 590 TWh of electricity demand in 2026 compared to 2022, roughly equivalent to adding at least one Sweden or at most one Germany."
 IEA energy consumption forecast
IEA energy consumption forecast
In a report published in October 2023, Alex de Vries (Ph.D. candidate at VU Amsterdam and founder of the digital-sustainability blog Digiconomist) has analyzed trends in AI energy use. He predicted that current AI technology could be on track to annually consume as much electricity as the entire country of Ireland (29.3 terawatt-hours per year).
De Vries' report also concludes that a continuation of current trends in AI capacity and adoption are set to lead to NVIDIA shipping 1.5 million AI server units per year by 2027. These 1.5 million servers, running at full capacity, would consume at least 85.4 terawatt-hours of electricity annually — more than what many small countries use in a year.
Technological Masterpiece or Ecological Disaster?
So the question arises: does GenAI lead us towards a brighter future with an easier workday, or does it inevitably push us towards an energy crisis amid climate change and energy conservation measures?
We cannot and do not intend to answer these questions in this article, but what we can say is that GenAI will inevitably continue to be a part of our lives, and the demand for GenAI will continue to rise. This is also evident from the forecasted figures described above. As also noted in the IEA report, "Future trends of the data center sector are complex to navigate, as technological advancements and digital services evolve rapidly." Thus, it is a matter of improving efficiency to decide which path we will take. Therefore, we want to explore this efficiency question from a technological perspective and see what this young sector already has to offer in this area.
Specialised Hardware
The majority of the computational power needed for AI today is provided by GPUs. While their architecture offers significantly better throughput than ordinary CPUs, due to the flexibility for which they were developed and designed, they also have notable problems and bottlenecks that throttle their performance for such large specialized applications. Hardware specifically designed for AI applications can deploy its computing power much more effectively and efficiently, as demonstrated by Google with their Tensor Processing Units (TPU).
"A TPU is an application-specific integrated circuit (ASIC) designed by Google for neural networks. TPUs possess specialized features, such as the matrix multiply unit (MXU) and proprietary interconnect topology that make them ideal for accelerating AI training and inference." "Cloud TPUs are optimized for training large and complex deep learning models that feature many matrix calculations, for instance building large language models (LLMs). Cloud TPUs also have SparseCores, which are dataflow processors that accelerate models relying on embeddings" Google TPU
Groq takes this even further by developing hardware specifically for use in LLMs.
"An LPU™ Inference Engine, with LPU standing for Language Processing Unit™, is a new type of processing system invented by Groq to handle computationally intensive applications with a sequential component to them such as LLMs. LPU Inference Engines are designed to overcome the two bottlenecks for LLMs – the amount of compute and memory bandwidth. An LPU system has as much or more compute as a Graphics Processor (GPU) and reduces the amount of time per word calculated, allowing faster generation of text sequences. With no external memory bandwidth bottlenecks an LPU Inference Engine delivers orders of magnitude better performance than Graphics Processor."
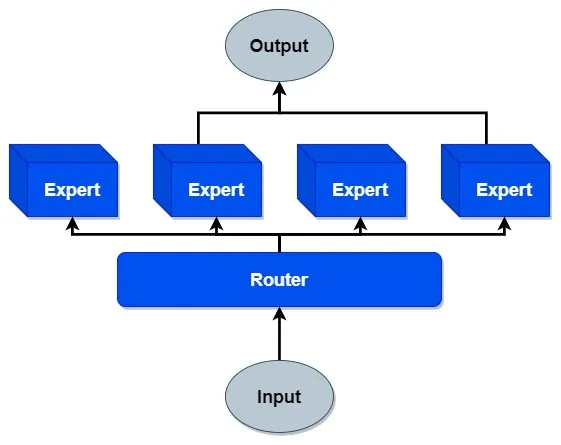
Expert Models Instead of Giant Monoliths
To enhance the accuracy and quality of model outputs, increasingly larger models trained with ever-larger datasets have emerged. This approach led to the creation of massive monolithic models that store all learned information in their extensive networks of neural nodes. Utilizing these models requires complex matrix computations throughout the entire network.
In contrast to these monoliths, an alternative approach aims to improve the overall quality of models. This method is known as Mixture of Experts (MoE). Fundamentally, an MoE model consists of a multitude of expert models and a gating mechanism. Instead of a single large model, a number of smaller specialized models are trained. These expert models are tailored to specific areas and are activated by the gating mechanism only when necessary for processing the input. The router (gating mechanism), which is also an ANN, is trained alongside the expert models. Although MoE models can also reach huge dimensions (such as GPT-4 with an estimated 16x111B parameters), the advantage lies in the fact that not one massive overall model but only a few smaller models need to be activated and computed.
Knowledge Distillation
Due to significant advancements in output quality, it has become possible to automate several steps previously performed through labor-intensive manual work by humans, using large language models (LLMs). This has also made it possible to transfer the behavior and quality of very large models to significantly smaller and less complex models, to a large extent. This technique is called "Knowledge Distillation".
The fundamental method involves training a student model using a dataset and employing the teacher model to create soft targets. Soft targets are probability distributions across the output categories. These are then utilized as training labels for the student model, alongside the one-hot encoded actual labels. This approach aims to minimize the discrepancies between the teacher's soft targets and the predictions made by the student model.
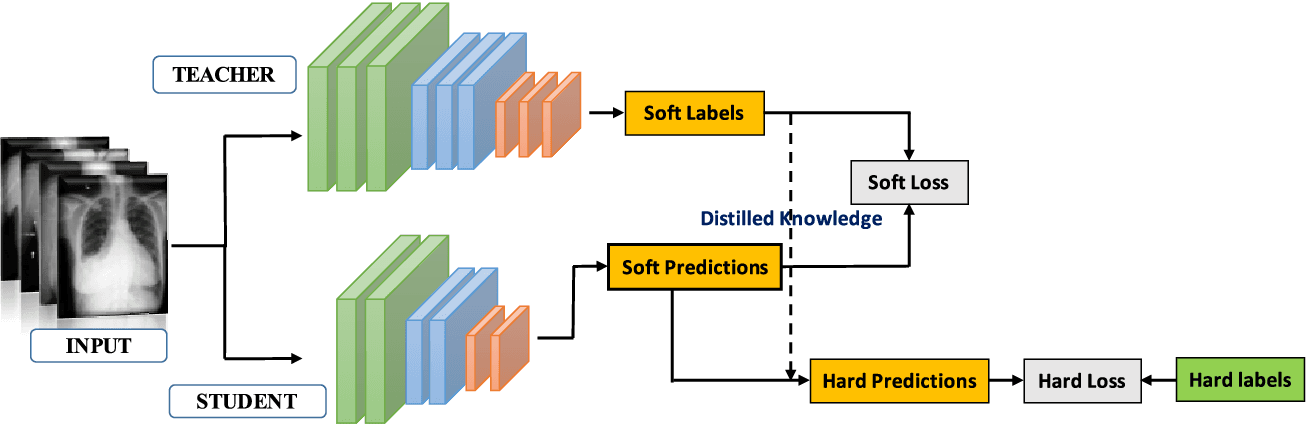
These significantly smaller student models can "mimic" their larger teacher models and deliver similar performance with substantially reduced computational effort.
Mixture-of-Depths
Transformer models consist of a series of transformer blocks that are processed sequentially. Each of these blocks is made up of attention layers, normalization layers, and feed-forward networks. The depth of these transformer blocks allows for the recognition and understanding of more nuanced relationships between words. In a traditional transformer, the compute capacity is distributed evenly, meaning every token must pass through the entire series of transformer blocks. However, not every token is equally complex or relevant for the final result.
 Decoder-only Transformer architecture
Decoder-only Transformer architecture
For this reason, the team at Google Deepmind developed a conditional computation technique called Mixture-of-Depths (MoD). This technique employs a learned routing mechanism to decide whether a token should pass through the current block or be routed around it. The MoD Transformer is given a computation budget, and only the top-k tokens in a block are processed.
 Visualisation of MoD principle
Visualisation of MoD principle
This brings several advantages. On one hand, it limits the required computational power, and on the other, it allows the Transformer to be optimized in two different directions. Either better accuracy with the same computing power (FLOPS) and even higher throughput can be achieved, or the same accuracy can be maintained with less computational power.

The team of Google Deepmind tried different settings and approaches for the MoD routing. The best results in this study were achieved when, in every second block, only every eighth token (12.5%) was processed.

As the approach of MoD - deciding whether to skip the block or not - is very similar to the approach of Mixture of Experts (MoE) - deciding which expert model to use -, the paper presented by Deepmind also evaluated the combination of these two approaches. In the combined approach, named MoDE, the routing decides between an expert model or skipping the block. This variant allowed the team to achieve even more efficient models than with the pure MoD approach.

Efficiency Enhancement through Layer Pruning
The scientific paper "The Unreasonable Ineffectiveness of the Deeper Layers" demonstrates, using popular open-weights model families such as Llama2, that a substantial portion of the layers in their neural networks can be removed without significantly degrading the quality of the output. To determine which layers should be removed, the Angular Distance between the input and output of the layers was measured. This metric indicates how similar or dissimilar the input and output are, thus reflecting how much the input has been altered. Layers with the least influence were removed.
The study found that generally, the deepest layers have the least influence, but the last or the last few layers have a very strong impact. The different models were tested immediately after pruning as well as after a "healing" process in which a Parameter Efficient Fine-Tuning (PEFT), using the QLORA technique, was conducted. In both cases, the models showed very consistent performance up to a certain degree of layer removal, with "healed" models demonstrating even more stable performance up to this point. However, beyond this point, the performance of all models rapidly deteriorates towards random behavior.
The paper states: "Importantly, we see a characteristic flat region of robust performance followed by a sharp transition to random accuracy at a pruning fraction around 45%-55% for models in the Llama-2 family, 35% for Mistral 7B, 25% for Phi-2, and 20% for models from the Qwen family. This implies that the essential knowledge required to achieve a model’s top score isn’t removed by significant layer removal – even though the fraction can be quite large(!) – until eventually that knowledge is lost at a critical model-dependent threshold.
Contrasting the curves with and without healing, we see that finetuning offers a modest improvement by better preserving the unpruned performance and pushing the phase transition to random guessing to slightly larger pruning fractions."

Regarding efficiency improvements, the authors also note: "In particular, the released version of Llama-2-70B spans 140 GB of memory and consumes approximately 3×10^10 FLOPs per token. With 4-bit quantization and a layer-pruning fraction of 50%, the model fits in approximately 17.5 GB of memory and requires roughly 1.5×10^10 FLOPs per token: quantization from 16-bit bfloats to 4-bit QLoRA precision reduces model memory by a factor of 4, but keeps FLOPs more or less the same, since calculations are performed in 16-bit precision; layer pruning will additionally reduce both memory and FLOPs by an amount equal to the layer-pruning fraction.These memory and compute requirements enable open-weight state-of-the-art models to be run and even finetuned efficiently on consumer-level GPUs without any CPU off-loading and with only minor performance trade-offs."
This method thus shows that current model generations are still very inefficient in resource usage and that these can be significantly reduced through appropriate measures, especially for the inference phase.
Reduction of Computational Efforts Through Quantization
Microsoft adopted a different approach to make models inherently more efficient and less computationally intensive from the ground up. To reduce the model size in terms of memory and computing power, the weights (parameters) within the model are often quantized, meaning their resolution is reduced. This is commonly done after training, in what is called post-training quantization. While this results in a slight loss of accuracy, this method is simple and allows the model to be proportionally scaled down.
To circumvent this post-training quantization, Microsoft in their study pursued the approach of reducing the resolution of parameters to the absolute minimum from the beginning. They attempted to realize the feed-forward networks using only binary (1-bit) parameters, meaning these could only take the values of 1 or -1. This means that while traversing the ANN, features from the preceding layer can have either a positive or negative impact on the activation of subsequent nodes. This model was named BitNet. In a second approach, they used ternary parameters, i.e., parameters with three possible states: -1, 0, and 1. Converted, this would correspond to 1.58 bits, which is why this model was called 'BitNet b1.58'. The additional zero state allows the model to filter features from the preceding layer.
With this model, the study authors were able to achieve extraordinary results. By reducing the usual 16-bit floating-point values in the ANNs to just these three states, no complex multiplications need to be performed in the matrix calculations, only integer additions of the input values (see figure).
 'BitNet b1.58' Pareto Improvement
'BitNet b1.58' Pareto Improvement
The study compared BitNet b1.58 with a reproduced FP16 LLaMA LLM. Despite this significant reduction, BitNet b1.58 was able to achieve almost identical results in various benchmarks as the LLaMA model.

This quantization is only performed in the FFNs and not in other parts of the Transformer, which means that the attention layers, etc., are computed at higher resolutions. Thus, the size of the model is not directly reduced by the resolution reduction, but the effect becomes more significant for models with more parameters. For a model with 3B parameters, the required memory is already reduced by a factor of 3.55. For a 70B model, the memory requirement is reduced by a factor of 7.16 and is 4.1 times faster. Moreover, a throughput of 2977 tokens/s is achieved, which corresponds to an 8.9-fold increase.
This significantly reduced computational power means not only a much smaller memory footprint and higher throughput but also a significant reduction in the energy required. According to the study, the BitNet b1.58 model with 70B can reduce the end-to-end energy consumption by 41.2 times compared to the LLaMA 70B model.
 'BitNet b1.58' energy consumption
'BitNet b1.58' energy consumption
 'BitNet b1.58' resource reduction and speed improvements
'BitNet b1.58' resource reduction and speed improvements
The improvements achieved through this approach are so significant that, from a resource perspective, BitNet models can compete with LLaMA models with significantly fewer parameters. For example, it is stated that:
- 13B BitNet b1.58 is more efficient, in terms of latency, memory usage and energy consumption, than 3B FP16 LLM.
- 30B BitNet b1.58 is more efficient, in terms of latency, memory usage and energy consumption, than 7B FP16 LLM.
- 70B BitNet b1.58 is more efficient, in terms of latency, memory usage and energy consumption, than 13B FP16 LLM.
Applying Foundation Models
However, RAG (Retrieval-Augmented Generation) systems can also contribute to the efficiency enhancement of AI applications. RAG systems allow for the 'integration' of proprietary information into LLMs using standard models, without the need to fine-tune these models or to train a model from scratch. Advanced techniques in retrieval further enhance the quality of the output while keeping the input context for the LLMs minimal.
Moreover, due to the independence from the specific LLM used, it is possible to swap out the LLM at any time, allowing any efficiency improvements in the LLMs to be directly incorporated into the system. This flexibility ensures that RAG systems can consistently benefit from the latest advancements in language model technology, enhancing both performance and efficiency.
Thinking outside the box
But there are also other technological solutions outside of the AI domain which can help to make AI more sustainable.
For example Paul Walsh (Data Scientist at Accenture) explained their approach of load shifting in a LinkedIn post as follows:
"One way to address sustainability in AI is to consider demand side interventions, which are initiatives that affect how and when electricity is used by consumers. This includes load shifting, whereby demand for electricity is rescheduled to a time when energy requirements can be more easily met by renewable resources. Essentially demand can be managed to meet renewable supply, to maximize the amount of renewable energy used in the mix. Indeed, by procuring renewable energy for neural network training, emissions can be reduced by a factor of between 30 and 40, compared to energy sourced from a fully fossil fueled grid. Such load shifting is highly feasible for many AI technologies, such as ML training, as they are not latency bound; developers can utilise compute resources in geographically dispersed regions with minimal little impact on the performance of production systems. This is also demonstrated by the work we have done in Accenture, whereby we can seamlessly move compute intensive workloads across widely dispersed geographic data centers to maximize the use of renewable energy with little to no impact on system performance. In essence, we are bringing computation to where renewable energy is available, rather than bringing renewable energy to the computation, exploiting the fact that transmitting electricity long distances is less efficient than sending code and data as photons over optical networks. This approach brings additional benefits in terms of driving demand to where renewable energy supplies are available. One of the main drawbacks of renewable energy is that it is intermittent, that is solar energy only works when the sun shines and wind renewables only work when weather conditions are right. While storage systems can be used to store energy, these systems are expensive and generally have limited capacity. Moreover, when supply exceeds demand many renewable energy sources are curtailed as demand is not available locally to meet supply. Load shifting solves the issue of intermittency and curtailment by bringing heavy compute loads to where supply can meet demand. This also drives demand for renewables, helping to finance and grow this critically important sector and help meet current and future demands in a sustainable way.
Load Shifting
Load shifting is a concept that has been applied to demand side management of energy, for example by scheduling the use of smart appliances to align their operation with the supply of renewable energy. Load shifting in this context refers to moving the compute load to a new region or new time of day where carbon intensity is lower. To address this, we strive to power AI by renewable energy when and where it’s available by shifting heavy compute loads. The idea is to identify regions that utilize renewable energy at a particular time of the day and create a system to automate the transfer of compute load for machine learning models to the most suitable region while monitoring the actual GPU/CPU usage. We do this by identifying cloud providers and geographic regions that support renewable energy around different time zones and then implement decision logic to automatically spin up the required computational infrastructure across the globe and automatically move compute loads to take advantage of the most optimal data center, all the while tracking energy usage of the models."
 Temporal and geographic load shifting of LLM training
Temporal and geographic load shifting of LLM training
Conclusion
While GenAI has ushered in profound advances in performance and capabilities, these benefits come at a steep environmental cost. The vast energy consumption required by these AI models highlights a critical need for innovative solutions to mitigate their ecological footprint.
Innovations such as specialized hardware, knowledge distillation, and advanced techniques like Mixture-of-Experts and Mixture-of-Depths demonstrate significant strides toward more sustainable AI practices. These approaches not only enhance the efficiency of AI models but also promise to reduce the substantial energy demands associated with their operation.
The discussion is further enriched by alternative strategies like load shifting, which align compute demands with the availability of renewable energy sources. This technique exemplifies a creative intersection of technology and sustainability, potentially easing the strain AI places on our energy resources.
Ultimately, the trajectory of GenAI will depend heavily on our commitment to aligning technological advancements with sustainable practices. If the current innovations and strategies are any indication, there is a hopeful path forward that balances the immense capabilities of AI with the imperative of environmental responsibility. The ongoing research and development in AI efficiency not only reflect a response to an immediate challenge but also pave the way for a future where technology and ecology coexist harmoniously.
Further Reading
Interested in building high-quality AI agent systems?
We prepared a comprehensive guide based on cutting-edge research for how to build robust, reliable AI agent systems that actually work in production. This guide covers:
- Understanding the 14 systematic failure modes in multi-agent systems
- Evidence-based best practices for agent design
- Structured communication protocols and verification mechanisms