Advanced RAG: Increase RAG Quality with ColBERT Reranker and llamaindex

Retrieval Augmented Generation (RAG) is one of the most useful models for integrating your own information and data with LLMs. Besides being a great piece of technology, RAG is quite intricate to set up and tune. There are many knobs to turn - and each of them has a significant impact on the quality of the final result (which is the answer of the LLM to your question).
One of the main concerns determining the quality of the final result is the 'context precision' - which is a metric for how well the retrieved documents match the context of the question. The better the documents match the context, the better the final answer will be.
In one of our last posts, we saw how to potentially increase the quality of the RAG model by using a recursive retrieval approach.
In this post, we will take a look at another approach - which can (and should) be combined with the recursive retrieval approach: how to use document reranking to get more relevant documents. We will start slowly by introducing the concept of reranking and answering the question why we need it. Followed by a hands-on guide on how to use a specific reranking model called 'ColBERT' and how to integrate it with the RAG model. Spoiler alert: We are going to use the highly acclaimed 'llamaindex' library for this.
How does reranking work and why do we need reranking?
With default RAG, the documents are retrieved using a semantic search algorithm. This algorithm is based on the similarity of the documents to the question. If the question is "How much does a house cost?", the similarity search uses vector embeddings to find documents that are similar to the question. The documents are then sent to the LLM - together with the question - to generate the final answer.
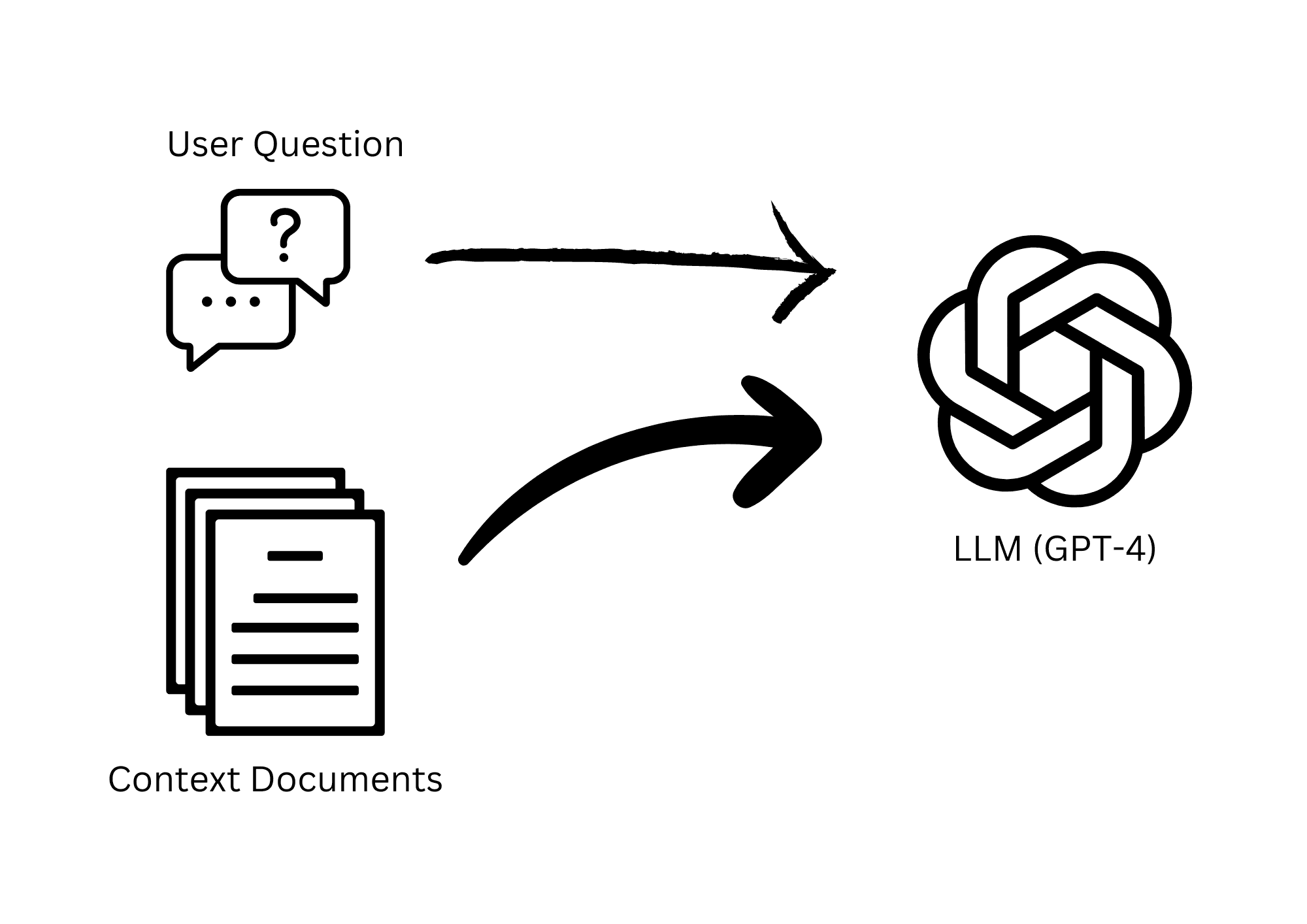 Simple RAG overview
Simple RAG overview
If there were a perfect embeddings model or a perfect semantic search algorithm, the documents would be perfectly matched to the question. But this is not the case. First - state of the art - embeddings models are not able to perfectly capture the semantic meaning of both the document texts and the users' questions. Second, as documents are most often automatically chunked into smaller pieces, they often do not contain a single semantic meaning - but many different topics. While there are different strategies to handle this, the problem remains.
The reranking strategy tries to tackle exactly this problem. It takes the documents retrieved by the semantic search and reranks them based on another model. This model is often a neural network that is trained to determine the relevance of a document to a question. The reranking model can be trained on a large dataset of questions and documents and is able to capture the relevance of a document to a question better than normal embedding models. And if not for that - at least it is sort of a "second opinion" on the relevance of a document to a question.
Another huge issue for semantic search is that embedding models - which are basically the core of semantic search - are mostly trained on general texts. Texts to be found on the internet. This means that they are not necessarily trained on texts that are relevant to your specific domain. Therefore, semantic search performance is oftentimes sub-par for specific domains. We call this the "out of domain" problem. Reranking can help to mitigate this problem by using a reranking model that is trained on specific domain texts. As reranking itself is not that complex - reranking models are easier to train on specific domain texts.
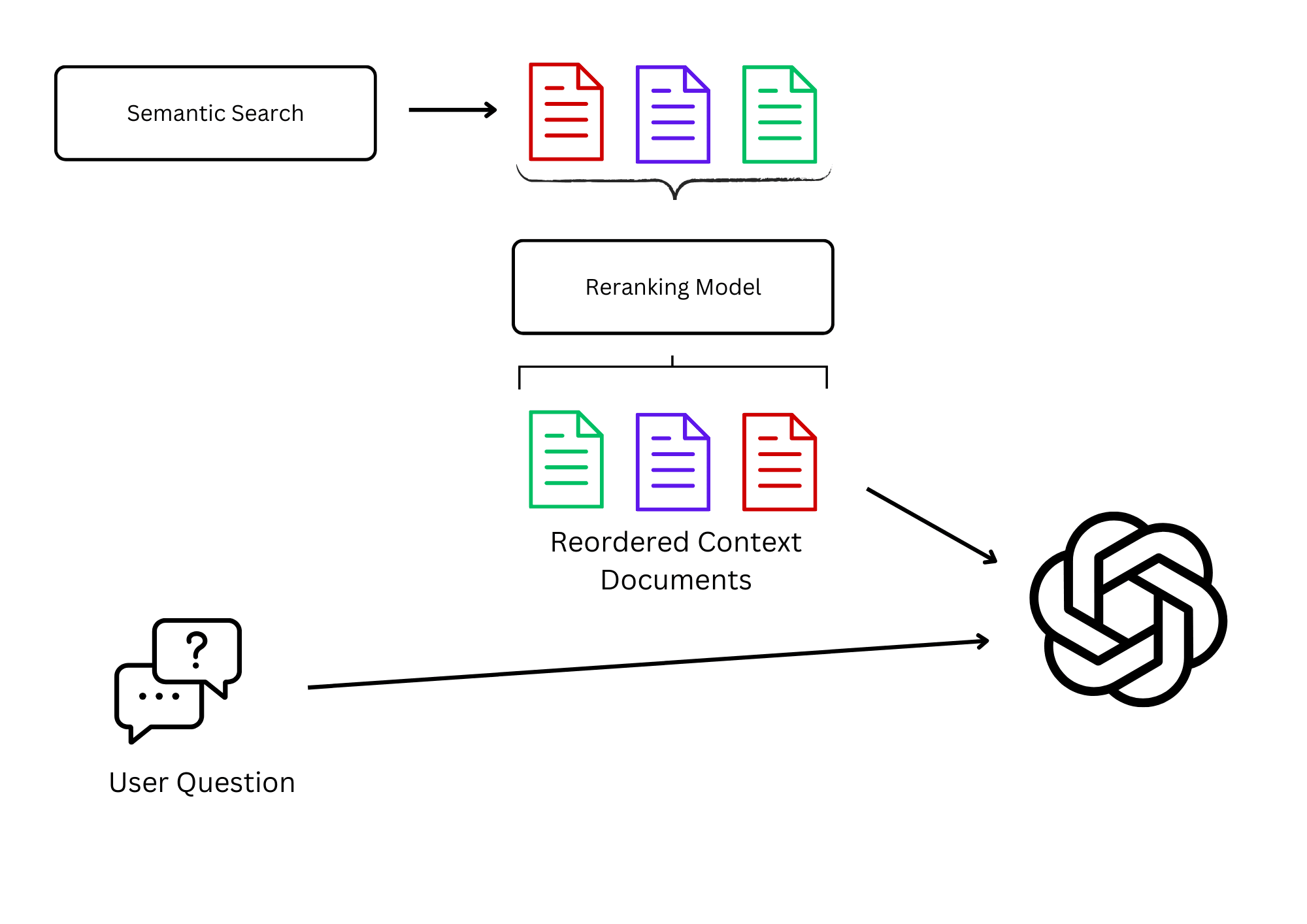 Reranking overview
Reranking overview
Enough theory - let's get our hands dirty and see how to implement reranking with a specific reranking model called 'ColBERT' and the llamaindex library.
How to implement RAG document reranking with ColBERT and llamaindex
We introduced llamaindex in one of our last posts. It is a great library for RAG and retrieval in general. See the before-mentioned post for more details about the library. Besides llamaindex's general appeal as a retrieval library, it also provides a simple way to integrate reranking models into your RAG pipeline. In this guide, we will use ColBERT as the reranking model.
ColBERT is a fast and accurate retrieval model, enabling scalable BERT-based search over large text collections in tens of milliseconds. Especially this last part is quite important. RAG itself is not a fast technology. All the LLM calls introduce latency. As reranking again needs to call a reranking model, additional latency is introduced. ColBERT is one of the fastest reranking models available and reduces this point of friction.
Let's get started by installing the required libraries:
If you want to follow along, download the sample data from our website.
Next, we can import the required libraries and define which OpenAI models
we want to use. Change the OPENAI_API_KEY to your own API key.
Optionally, you might want to enable debug logging to see what "magic" llamaindex is performing under the hood:
Now we can load our document, divide it into smaller chunks and create
a VectorStoreIndex. Llamaindex once again makes this quite easy:
To get our ColBERT reranker as part of the llamaindex pipeline, we can
simply add it as a node postprocessor to the llamaindex query engine.
The query engine then basically executes the following tasks:
- Creates a query vector from the question
- Retrieves the most similar documents from the index
- Reranks the documents using the ColBERT model
- Sends the reranked documents to the LLM
That's all we need for now. We can now use the query_engine to ask our
LLM questions and get answered based on our indexed documents.
Furthermore, the ColBERT reranker will rerank the documents before they
are sent to the LLM.
Interested in building high-quality AI agent systems?
We prepared a comprehensive guide based on cutting-edge research for how to build robust, reliable AI agent systems that actually work in production. This guide covers:
- Understanding the 14 systematic failure modes in multi-agent systems
- Evidence-based best practices for agent design
- Structured communication protocols and verification mechanisms
See the reranker in action
Up until now, we could not really see the impact of the reranker. Let's print the retrieved document nodes to see the impact of the reranker.
This snippet will print the retrieved documents alongside two scores:
-
The
retrieval scoreis the score that the semantic search algorithm assigned to the document. The higher the score, the more similar the document is to the question - according to the semantic search algorithm. -
The
reranking scoreis the score that the ColBERT reranker assigned to the document. The higher the score, the more relevant the document is to the question - according to the ColBERT reranker.
If you analyze the printed output, you'll see that the order of the documents by reranking score is often different from the order of the documents by retrieval score. More often than not, the new document order represents a better match to the question - keep in mind, that the first document should be the most relevant one.
Conclusion
In the evolving landscape of Retrieval Augmented Generation (RAG) technologies, ensuring the precision and relevance of retrieved documents is paramount for enhancing the quality of responses generated by Language Models (LLMs). This article has delved into the sophisticated strategies of document reranking, specifically employing the ColBERT reranker in conjunction with the llamaindex library, to address the inherent challenges posed by semantic search algorithms and the limitations of embedding models.
The integration of ColBERT as a reranking model represents a significant leap forward in refining the document retrieval process. By offering a "second opinion" on the relevance of documents to specific queries, ColBERT effectively mitigates the issues associated with the "out of domain" problem, thereby enhancing the contextual accuracy of documents retrieved for LLMs. The practical guide provided herein not only elucidates the process of implementing this reranking model but also underscores the importance of such technologies in achieving more precise, domain-specific search results.
As we have seen, the combination of llamaindex's robust retrieval capabilities with ColBERT's fast and accurate reranking presents a compelling solution to the challenges of ensuring context precision in RAG models. This synergy not only improves the quality of LLM responses but also paves the way for more sophisticated and domain-specific applications of RAG technologies.
In conclusion, the advancement of reranking techniques, exemplified by the integration of ColBERT with llamaindex, marks a critical step towards optimizing the efficiency and effectiveness of RAG models. By focusing on the precision of document retrieval, we can significantly enhance the quality of generated responses, offering more accurate, relevant, and contextually rich information to users. As we continue to explore and refine these technologies, the potential for creating more intelligent, responsive, and tailored AI-driven solutions becomes increasingly tangible.